So, I hear you like emulators. It turns out that Go is a great language for writing retro-computing emulators. Here are the ones that I have tried so far:
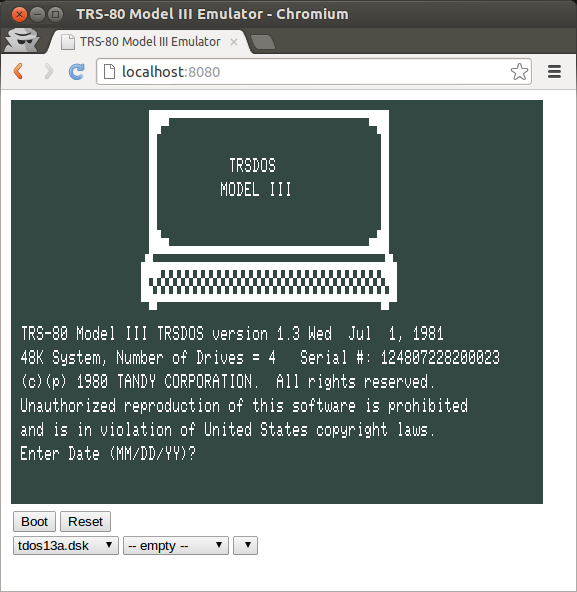
I really liked this one because it avoids the quagmire of OpenGL or SDL dependencies and runs in your web browser. I had a little trouble getting it going so if you run into problems remember to execute the trs80 command in the source directory itself. If you’ve used go get github.com/lkesteloot/trs80 then it will be $GOPATH/src/github.com/lkesteloot/trs80.
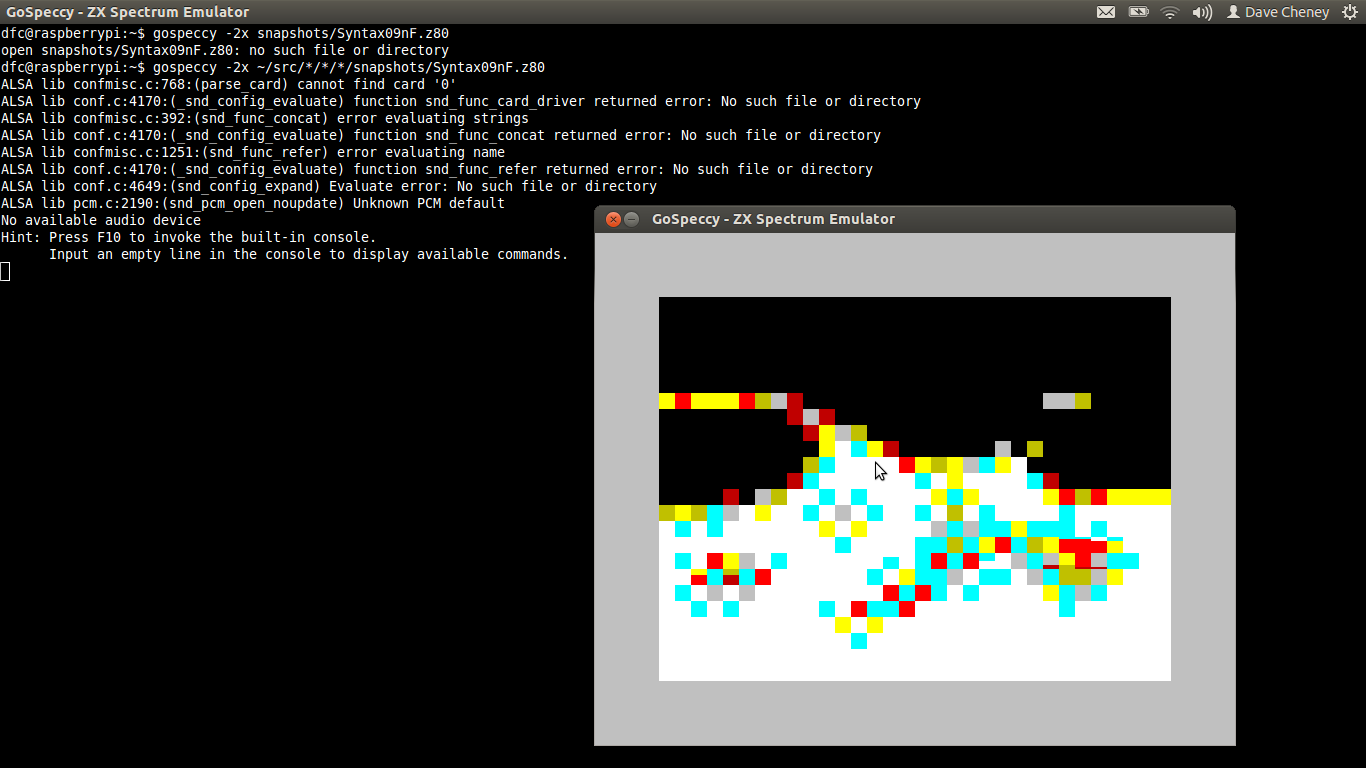
GoSpeccy was the first emulator written in Go that I am aware of, Andrea has been quietly hacking away well before Go hit 1.0. I’ve even been able to get GoSpeccy running on a Raspberry Pi, X forwarded back to my laptop. Here is a screenshot running the Fire104b intro by Andrew Gerrand
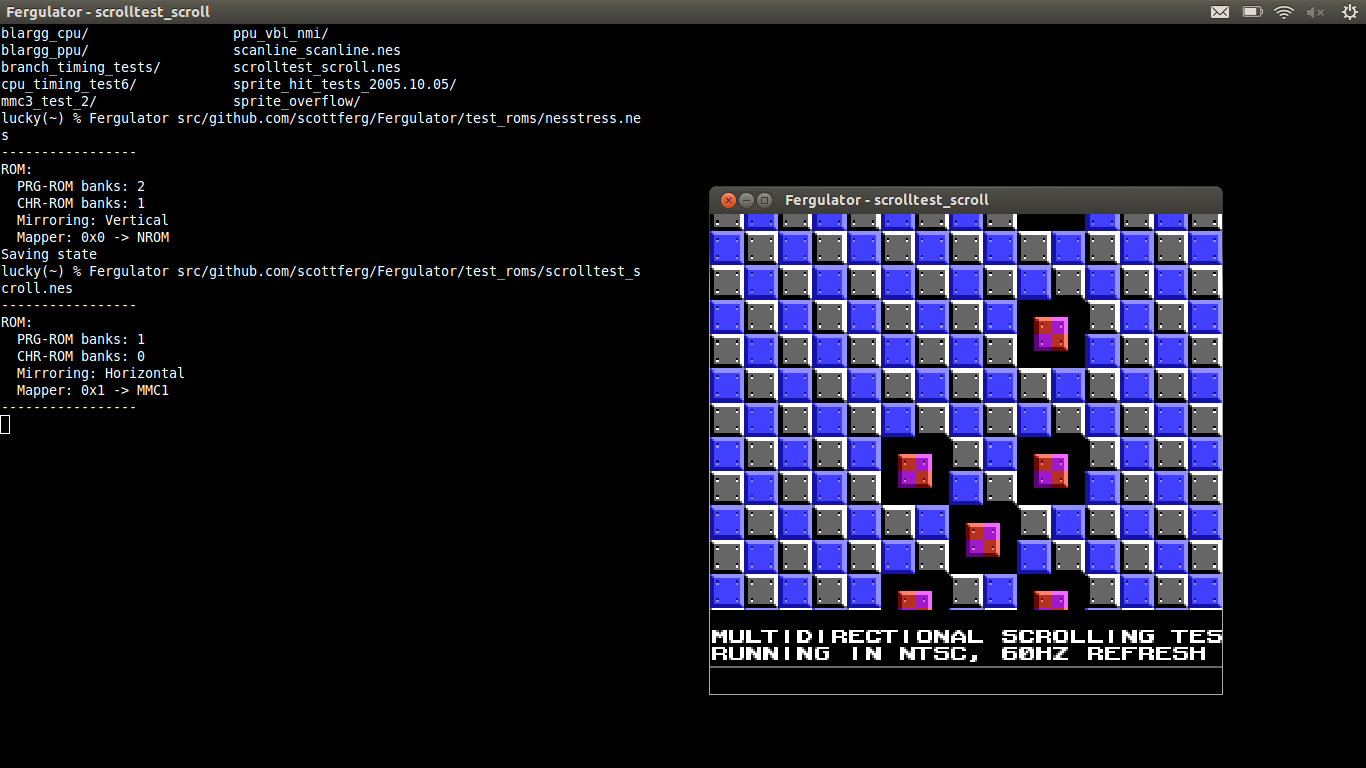
Like GoSpeccy, Fergulator shows the power of Go as a language for writing complex emulators, and the power of go get to handle packages with complex dependencies. Here are the two commands that took me from having no NES emulation on my laptop, to full NES emulation on my laptop.
lucky(~) sudo apt-get install libsdl1.2-dev libsdl-gfx1.2-dev libsdl-image1.2-dev libglew1.6-dev libxrandr-dev
lucky(~) % go get github.com/scottferg/Fergulator
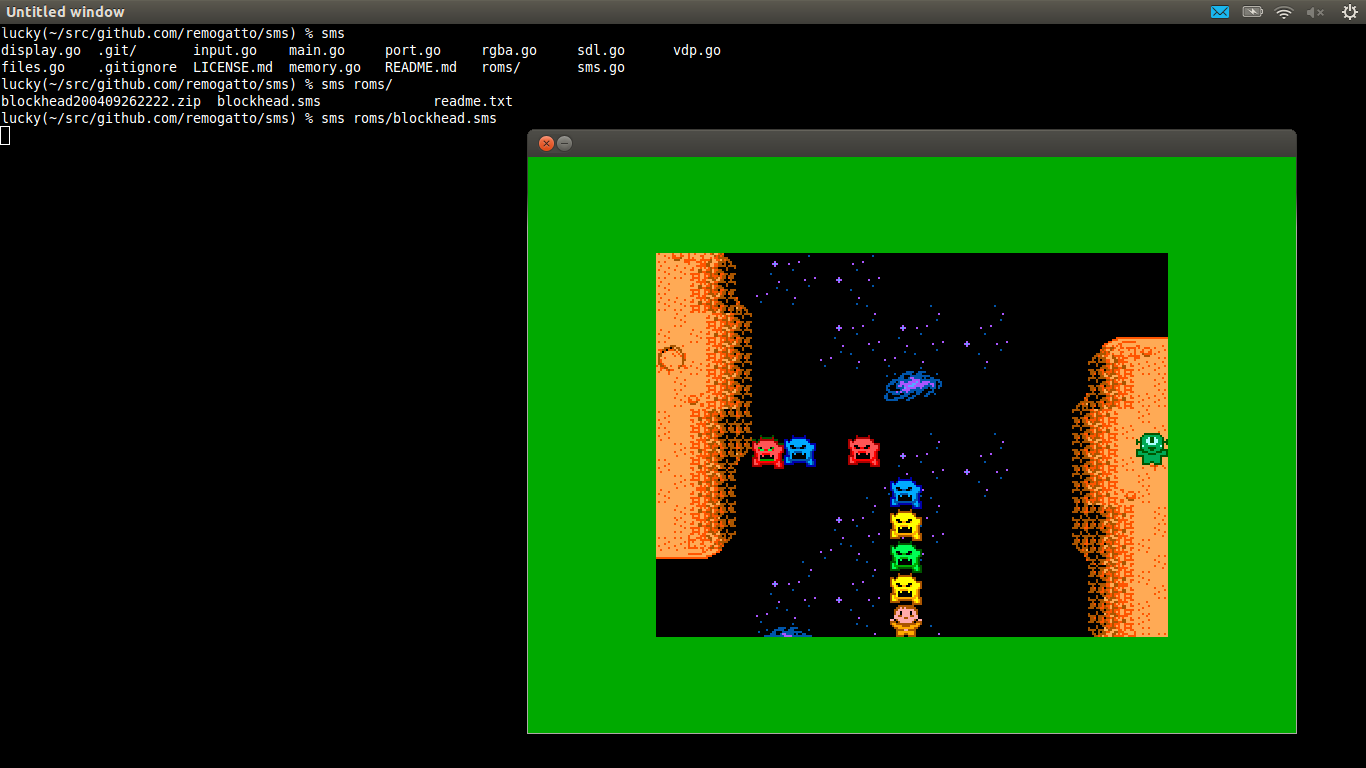
What’s this? Another emulator for Andrea Fazzi ? Why, yes it is. Again, super easy to install with go get -v github.com/remogatto/sms. Sadly there are no sample roms included with sms due to copyright restrictions, so no screenshot.Update: Andrea has included an open source ROM so we can have a screenshot.
Update: Several Gophers from the wonderful Go+ community commented that there are still more emulators that I haven’t mentioned.
dcpu by Jim Teeuwen, an implementation of Notch’s DCPU specification.
This afternoon Oleksandr Tymoshenko posted an update on the state of FreeBSD on ARMv6 devices. The takeaway for Raspberry Pi fans is things are working out nicely. A few days ago a usable image was published allowing me to do some serious testing of the Go freebsd/arm port.
So, what works? Pretty much everything
[root@raspberry-pi ~]# go run src/hello.go
Hello, 世界
For the moment cgo and hardware floating point is disabled. I disabled cgo support early in testing after some segfaults, but it shouldn’t be too hard to fix. The dist tool is currently failing to auto detect1 support for any floating point hardware.
This could be because the auto detection is broken on freebsd/arm, but possibly this kernel image does not enable the floating point unit. I’ll update this post when I’ve done some more testing.
At the moment performance is not great, even by Pi standards. The SDCard runs in 1bit 25mhz mode, and I believe the caches are disabled or set to write though. The image has been stable for me, allowing me to compile Go, and various ports required by the build scripts.
This month, Go turns three, and this is the video that started it all for me.
As a testiment to skills of Pike, Thompson and Griesemer, the ideals presented in 2009 have survived virtually unaltered into the Go 1.0 release earlier this year. Rewatching this video recently I was reminded that when changes were required they were almost always to the standard library, which underwent constant revision (aided by the gofix tool) until the 1.0 code freeze. From my notes, the important language level changes were
By early 2010, semicolons had been removed from the written syntax (although still present implicitly inside the compiler).
The semantics of non-blocking send and recieve and channel closure were explored and altered a number of times before arriving at their final form.
Maps dropped the confusing map[key] = nil, false deletion form, replaced with more regular delete(map, key), although some bemoaned the addition of another language builtin.
The constant literal syntax has been improved to make it clearer when constructing large constant literal forms.
Lastly, the builtin error type replaced the original os.Error interface type.
I’ve been doing some work improving the code generation of the 5g compiler, which is the Go compiler for arm. These notes also apply to the 6g and 8g compilers for amd64 and 386 respectively.
For this discussion we’ll use a very simple package.
package addr
func addr(s[]int) *int { return &s[2] }
To see the assembly produced by compiling this package we use the -S flag. -S can be passed directly to the compiler with go tool 5g -S addr.go, but it is simpler (and more portable) to use the -gcflags flag on the go tool itself.
This is quite a lot of code for a one line function. One of the reasons for this is s is a slice, whose length is not known at compile time, so the compiler must insert a bounds check. We can tell the compiler to not emit bounds checks with the -B flag.
% go build -gcflags=-SB addr.go # command-line-arguments --- prog list "addr" --- 0000 (/home/dfc/src/addr.go:3) TEXT addr+0(SB),$0-16 0001 (/home/dfc/src/addr.go:4) MOVW $s+0(FP),R0 0002 (/home/dfc/src/addr.go:4) MOVW 0(R0),R0 0003 (/home/dfc/src/addr.go:4) ADD $8,R0 0004 (/home/dfc/src/addr.go:4) MOVW R0,.noname+12(FP) 0005 (/home/dfc/src/addr.go:4) RET ,
It is important to note that -B is an unsupported flag. The goal of Go is a safe language, one where array subscripts are bounds checked when they are not provably safe. Go already elides bounds checks when you use range loops, and future compilers will improve this. It is also important to note that none of the builders test -B so it might even generate incorrect code. In summary, when the compiler improves, -B will go away, so don’t get too attached.
One other interesting flag is -N, which will disable the optimisation pass in the compiler
I think the only thing that is useful about this example is, it’s good thing the optimiser is on by default because there are some strange things going on here, for example line 0002, and the unreachable branch at line 0012.
The last thing to talk about is the output of 5g is not the final code that is executed. Aside from the usual work of a linker, 5l does several transformations on the code which are important to understand.
Here we use objdump -dS to dump the addr function as it is compiled into the executable. The first six instructions, starting at 10c00, are the function preamble that deals with segmented stacks which is inserted automatically by the 5l.
Taking it further
There are several other compiler flags which are useful when debugging or optimising your Go code.
-g will output the steps a the compiler is a taking at a very low level. The discussion of the output format is outside the scope of this article. Personally I find it easier to add a warn statement which will tell me the source line the compiler was working on at the time.
-l will disable inlining (but still retain other compiler optimisations). This is very useful if you are investigating small methods, but can’t find them in objdump.
-m is mainly a frontend switch and outputs details about escape analysis and inlining choices.
Yesterday Mikio Hara committed a new package for ipv4 handling to the go.net repository. I wanted to recognise Mikio’s work for two reasons.
The level of detail and control this package offers is, in my opinion, unmatched by any other language. If you’re using C or C++, then you have the raw power of setsockopt(2) and ioctl(2) available, but you also have no guide or safety rail when using them. Mikio’s package provides exquisite control over ipv4 minutia without sacrificing the safety that Go provides.
The package is a fantastic example of using conditional compilation and embedding to build a very low level package that works across all the supported Go platforms. This package compiles cleanly on Linux, *BSD, OS X and Windows without resorting to the lowest common denominator or using a single ifdef. If you are looking for examples on how to structure your code using build tags, or looking for ways to work within the Go1 API, you should study this package.
The Raspberry Pi has captured the imagination of hackers and makers alike. While it certainly wasn’t the first ARM development board on the market, its bargin basement price tag and the charitablephilosophy of its inventors has sparked a huge interest in this little ARM system. What could be more appropriate for a new generation of programmers than a modern, safe and efficient programming language for their projects, Google Go.
This post describes the steps for installing Google Go from source on the Raspberry Pi. At the time of this post, trunk contains many improvements for ARM processors, including full support for cgo, which are not available in Go 1.0.x. It is expected that these enhancements will be available when Go 1.1 ships next year. If you are reading this post in September 2013, then it’s likely you will want to use the version of Go shipping with your operating system distribution rather than these instructions.
Update May, 2013 If you want to save yourself some time, precompiled binary releases of Go 1.1 for linux/arm are available. Please see the Unofficial ARM tarballs link at the top of the page.
Setting up your Pi
Before you compile Go on your Pi you should follow these steps to ensure a successful compilation. Briefly summarised, they are:
Install Raspbian
Configure your memory split
Add some swap
Install Raspbian
The downloads page on the Raspberry Pi website contains links to SD card images for various Linux distributions. This tutorial recommends the Raspbian wheezy flavour of Debian. Follow the instructions for creating an SD card image and continue to the next step once you have ssh’d into your Raspbian installation.
Configure your memory split
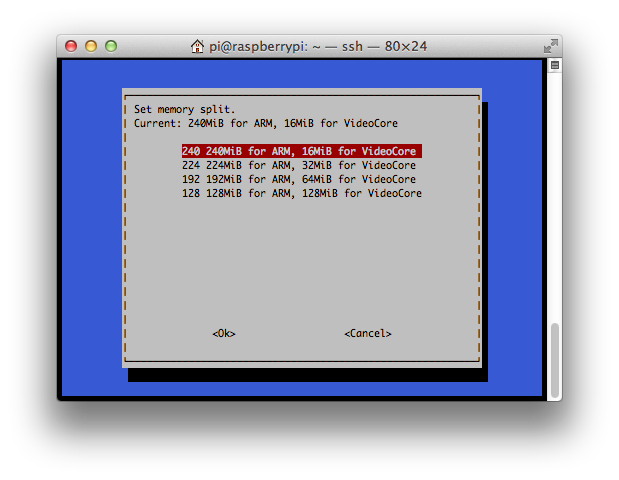
The Pi comes with 256mb of memory which is shared between the video subsystem and the main processor. Compiling and linking Go programs can consume over 100mb of ram so it is recommended that the memory split be adjusted in favor of the main processor, at least while working with Go code. The Raspbian distribution makes this very easy with the raspi-config utility
% sudo raspi-config
Then reboot your system
% sudo shutdown -r now
Add some swap
To run the full test suite you will need some swap. This can be accomplished a variety of ways, using an external USB hard drive, or swapping over NFS. I’ll describe how to setup a NFS swap partition as this is the configuration I am using to generate this tutorial.
% sudo dd if=/dev/zero of=/import/nas/swap bs=1024 count=1048576 1048576+0 records in 1048576+0 records out 1073741824 bytes (1.1 GB) copied, 136.045 s, 7.9 MB/s % sudo losetup /dev/loop0 /import/nas/swap % sudo mkswap /dev/loop0 Setting up swapspace version 1, size = 1048572 KiB no label, UUID=7ba9443d-c64c-416f-9931-39e3e2decf0f % sudo swapon /dev/loop0 % free -m total used free shared buffers cached Mem: 232 78 153 0 0 24 -/+ buffers/cache: 52 179 Swap: 1123 15 1108
Installing the prerequisites
Raspbian comes with almost all the tools you need to compile Go already installed, but to be sure you should install the following packages, described on the golang.org website.
% sudo apt-get install -y mercurial gcc libc6-dev
Cloning the source
% hg clone -u default https://code.google.com/p/go $HOME/go warning: code.google.com certificate with fingerprint 9f:af:b9:ce:b5:10:97:c0:5d:16:90:11:63:78:fa:2f:37:f4:96:79 not verified (check hostfingerprints or web.cacerts config setting) destination directory: go requesting all changes adding changesets adding manifests adding file changes added 14430 changesets with 52478 changes to 7406 files (+5 heads) updating to branch default 3520 files updated, 0 files merged, 0 files removed, 0 files unresolved
Building Go
% cd $HOME/go/src % ./all.bash
If all goes well, after about 90 minutes you should see
ALL TESTS PASSED
---
Installed Go for linux/arm in /home/dfc/go
Installed commands in /home/dfc/go/bin
If there was an error relating to out of memory, or you couldn’t configure an appropriate swap device, you can skip the test suite by executing
% cd $HOME/go % ./make.bash
as an alternative to ./all.bash.
Adding the go command to your path
The go command should be added to your $PATH
% export PATH=$PATH:$HOME/go/bin % go version go version devel +cfbcf8176d26 Tue Sep 25 17:06:39 2012 +1000
Hello. Thanks for reading this article. Now that Go 1.1 has been released an updated version of this article is available.
Whoa there! This article is out of date. The release of Go 1.5 has invalidated everything below and you really should read this article instead.
Introduction
Go provides excellent support for producing binaries for foreign platforms without having to install Go on the target. This is extremely handy for testing packages that use build tags or where the target platform is not suitable for development.
Support for building a version of Go suitable for cross compilation is built into the Go build scripts; just set the GOOS, GOARCH, CGO_ENABLED and possibly GOARM correctly and invoke ./make.bash in go/src. Therefore, what follows is provided simply for convenience.
Getting started
1. Install Go from source. The instructions are well documented on the Go website, golang.org/doc/install/source. A summary for those familiar with the process follows.
% hg clone https://code.google.com/p/go
% cd go/src
% ./all.bash
Sourcing crosscompile.bash provides a go-$GOOS-$GOARCH function for each platform, you can use these as you would the standard go tool. For example, to compile a program to run on linux/arm.
% cd $GOPATH/github.com/davecheney/gmx/gmxc
% go-linux-arm build
% file ./gmxc
./gmxc: ELF 32-bit LSB executable, ARM, version 1 (SYSV),
statically linked, not stripped
This file is not executable on the host system (darwin/amd64), but will work on linux/arm.
Some caveats
Cross compiled binaries, not a cross compiled Go installation
This post describes how to produce an environment that will build Go programs for your target environment, it will not however build a Go environment for your target. For that, you must build Go directly on the target platform. For most platforms this means installing from source, or using a version of Go provided by your operating systems packaging system.
No cgo in cross platform builds
It is currently not possible to produce a cgo enabled binary when cross compiling from one operating system to another. This is because packages that use cgo invoke the C compiler directly as part of the build process to compile their C code and produce the C to Go trampoline functions. At the moment the name of the C compiler is hard coded to gcc, which assumes the system default gcc compiler even if a cross compiler is installed.
GOARM flag needed for cross compiling to linux/arm.
Because some arm platforms lack a hardware floating point unit the GOARM value is used to tell the linker to use hardware or software floating point code. Depending on the specifics of the target machine you are building for, you may need to supply this environment value when building.
% GOARM=5 go-linux-arm build
As of e4b20018f797 you will at least get a nice error telling you which GOARM value to use.
$ ./gmxc
runtime: this CPU has no floating point hardware, so it cannot
run this GOARM=7 binary. Recompile using GOARM=5.
By default, Go assumes a hardware floating point unit if no GOARM value is supplied. You can read more about Go on linux/arm on the Go Language Community Wiki.
2007 was a different time for languages. While Java held the popular crown, the mainstream programming community were still coming to terms with Java 6. Released 3 months earlier, it was very much an evolution of the Java 5 watershed. Its arrival heralded the end of life for Java 1.4 and represented an opportunity to draw a line in the sand for a Java that assumed Generics and Annotation Processing. In turn this created an opening for alternate JVM languages like Groovy, JRuby and Scala, raising the discussion to a din and giving developers pause to consider a wider field of alternatives.
At the time, Yegge left me with the impression that D was his pick for the Next Big Language, although he suggested that the Next Big Language was not amongst the set on the market at that time. This fit my world view as I had just discovered D and felt chuffed to be on the inside track of this up and coming language. D had everything that opened and shut; template metaprogramming, fast compilation, function literals, C like syntax and a memory model that someone coming from Java could grok. Two years later however, D was still stuck in 2007. This was in part due to the infighting between the standard library camps who had failed to learn from the mistakes of the Java class library and were busily adding bloat and verbosity to Phobos and Tango. Similarly those who wanted to hack on the language were bifurcated by the closed source DMD compiler and the slow moving gdc frontend. D may have been an excellent choice for those who wanted a better C++, but it wasn’t clear if actually was a market for a better C++.
At this same point in 2007, Rob Pike and Robert Griesemer were sitting, probably not far away from my office at the time, thinking the same thing. It took two years, and the addition of stalwarts like Ken Thompson, Russ Cox and Ian Lance Taylor for their creation to reach fruition; and several more years for their new language to gain mainstream awareness.
Therefore, with the benefit of hindsight that history provides, I would like to revisit the major points of Yegge’s Next Big Language, and address them in the context of Go.
Update: Go is licenced under a BSD like licence, not the MIT licence. Thanks to the astute readers on HN for noticing my mistake.
Update 2: The names of the D standard libraries are Phobos and Tango. I have also updated the list in rule 5 to be a table at the request by request.
The NBL does not replace C++, the NBL is garbage collected.
As Yegge said at the time, there will always be a bunch of engineers who think that’s evil, and they’ll continue to use C++. I think the experiences of D have borne that out, but more importantly there is a lesson to be learnt that there is no one single language that is appropriate for all tasks. Go, as a general purpose language, is a mixture of decisions and tradeoffs that place it in the best position to reach and be relevant to mainstream developers. The choice of a garbage collected runtime was obvious for a language that held concurrency as one of its core tenets.
The NBL will have corporate backing
Looking at the origins of Java, Python, C++, Scala, with the notable exception of Ruby, Go follows the trend of having a strong corporate or academic benefactor. Google are generous and passionate supporters of Go, and while the Authors work for Google, there are many external contributors who have made substantial ongoing contributions to the language. Just as importantly, the entire project is BSD licensed (something which D was not able to do, and suffered for it) and driven by passionate, opinionated leaders. To my mind, this is the best of both worlds.
I think of this as a courtesy to people who already have an investment in an existing mainstream language. The syntax of Go is spartan, and takes little opportunity to further this area of language design, instead leaving that to Scala or Haskell. Go’s most powerful claims in this area would be the adoption of the go fmt source code formatting tool and the elision of semicolons, both of which have a subtle, but profound impact.
Rule #2: Dynamic typing with optional static types
Go answers Yegge’s call by providing a static language with dynamic typing features through the pervasive use of interfaces and automatic type deduction.
Rule #3: Performance. The NBL will perform about as well as Java
For workloads which have at least some IO component, Go is as fast as Java or C++. It produces efficient, statically compiled programs that can be deployed trivially without the overhead of a large runtime framework. Go programs perform as fast on their first cycle as their last, without the need for witchcraft often associated with languages targeting a JITed interpretor. While it may not be possible, because of Go’s more conservative approach to pointer arithmetic and memory safety, to best the raw computational speed of C, performance is a core design goal of the language and will continue to improve over time. Even now, I have no hesitation in recommending Go to displace any programming task which would previously have been targeted towards Java.
By comparison with Eclipse or Visual Studio, the automated tools available to Go programmers are limited. Taking the age of the language into account, this is to be expected. Interestingly for authors of Go programs, the experience is more akin to their dynamic cousins like Python and Ruby, who bucked the trend years before by adopting simple programming environments that offered little more than syntax highlighting.
I’ll move quickly through Yegges list of must have features as their discussion would span several posts alone.
Object-literal syntax for arrays and hashes
Yes
Array slicing and other intelligent collection operators
Yes
Perl 5 compatible regular expression literals
No
Destructuring bind (e.g. x, y = returnTwoValues())
Yes
Function literals and first-class, non-broken closures
Yes
Standard OOP with classes, instances, interfaces, polymorphism, etc.
No
Visibility quantifiers (public/private/protected)
Yes
Iterators and generators
No
List comprehensions
No
Namespaces and packages
Yes
Cross-platform GUI
No
Operator overloading
No
Keyword and rest parameters
Yes
First-class parser and AST support
Yes
Static typing and duck typing
Yes
Type expressions and statically checkable semantics
Yes
Solid string and collection libraries
Yes
Strings and streams act like collections
No
The final tally is 11 affirmative, 7 negative, but with the addition of items from the next paragraph, specifically threading and continuations, I believe Go answers many of the import must haves for a mainstream language entrant. While languages like Julia or Rust approach 100% coverage of Yegge’s laundry list, it is still to be seen if they will achieve mainstream adoption.
Go provides outstanding cross operating system and cross architectural support. Rather than adopt Java’s lowest common denominator approach, Go allows both an escape hatch to access features specific to one platform, and a simple file name based conditional compilation system to provide platform specific implementations without having to resort to interfaces.
Rereading Yegge’s essay five years after it was published, it is clear to me that even, as Yegge claimed, he had no knowledge of the ruminations of his colleagues, the stage was set for the Next Big Language.
I believe that Go is a strong contender for the Next Big Language and I urge you to give it serious consideration.
This week there was a discussion on the golang-nuts mailing list about an idiomatic way to update a slice of structs. For example, consider this struct representing a set of counters.
type E struct { A, B, C, D int }
var e = make([]E, 1000)
Updating these counters may take the form
for i := range e { e[i].A += 1 e[i].B += 2 e[i].C += 3 e[i].D += 4] }
Which is good idiomatic Go code. It’s pretty fast too
BenchmarkManual 500000 4642 ns/op
However there is a problem with this example. Each access the ith element of e requires the compiler to insert an array bounds checks. You can avoid 3 of these checks by referencing the ith element once per iteration.
for i := range e { v := &e[i] v.A += 1 v.B += 2 v.C += 3 v.D += 4 }
By reducing the number of subscript checks, the code now runs considerably faster.
BenchmarkUnroll 1000000 2824 ns/op
If you are coding a tight loop, clearly this is the more efficient method, but it comes with a cost to readability, as well as a few gotchas. Someone else reading the code might be tempted to move the creation of v into the for declaration, or wonder why the address of e[i] is being taken. Both of these changes would cause an incorrect result. Obviously tests are there to catch this sort of thing, but I propose there is a better way to write this code, one that doesn’t sacrifice performance, and expresses the intent of the author more clearly.
func (e *E) update(a, b, c, d int) { e.A += a e.B += b e.C += c e.D += d }
for i := range e { e[i].update(1, 2, 3, 4) }
Because E is a named type, we can create an update() method on it. Because update is declared on with a receiver of *E, the compiler automatically inserts the (&e[i]).update() for us. Most importantly because of the simplicity of the update() method itself, the inliner can roll it up into the body of the calling loop, negating the method call cost. The result is very similar to the hand unrolled version.
BenchmarkUpdate 500000 2996 ns/op
In conclusion, as Cliff Click observed, there are Lies, Damn Lies and Microbenchmarks. This post is an example of a least one of the three. My intent in writing was not to spark a language war about who can update a struct the fastest, but instead argue that Go lets you write your code in a more expressive manner without having to trade off performance.
You can find the source code for the benchmarks presented in this below.
package b
import "testing"
// SIZE=1000 results (core i5 late 2011 mac mini, 10.7.3) // % go test -v -run='XXX' -bench='.' // PASS // BenchmarkUpdate 500000 2996 ns/op // BenchmarkManual 500000 4642 ns/op // BenchmarkUnroll 1000000 2824 ns/op
type E struct { A, B, C, D int }
func (e *E) update(a, b, c, d int) { e.A += a e.B += b e.C += c e.D += d }
var SIZE = 1000 // needed to make a valid testable package
func TestNothing(t *testing.T) {}
func assert(e []E, b testing.B) { for _, v := range e { if v.A != b.N || v.B != b.N2 || v.C != b.N3 || v.D != b.N4 { b.Errorf("Expected: %d, %d, %d, %d; actual: %d, %d, %d, %d", b.N, b.N2, b.N3, b.N*4, v.A, v.B, v.C, v.D) } } }
func BenchmarkUpdate(b *testing.B) { var e = make([]E, SIZE) for j := 0; j < b.N; j++ { for i := range e { e[i].update(1, 2, 3, 4) } } b.StopTimer() assert(e, b) }
func BenchmarkManual(b *testing.B) { var e = make([]E, SIZE) for j := 0; j < b.N; j++ { for i := range e { e[i].A += 1 e[i].B += 2 e[i].C += 3 e[i].D += 4 } } b.StopTimer() assert(e, b) }
func BenchmarkUnroll(b *testing.B) { var e = make([]E, SIZE) for j := 0; j < b.N; j++ { for i := range e { v := &e[i] v.A += 1 v.B += 2 v.C += 3 v.D += 4 } } b.StopTimer() assert(e, b) }