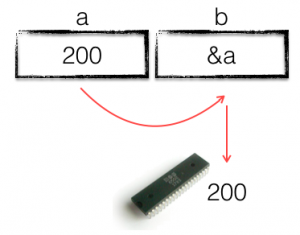
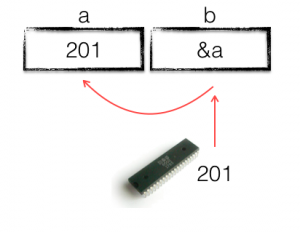
In my previous post I showed that Go maps are not reference variables, and are not passed by reference. This leaves the question, if maps are not references variables, what are they?
For the impatient, the answer is:
A map value is a pointer to a
runtime.hmapstructure.
If you’re not satisfied with this explanation, read on.
What is the type of a map value?
When you write the statement
m := make(map[int]int)
The compiler replaces it with a call to runtime.makemap, which has the signature
// makemap implements a Go map creation make(map[k]v, hint) // If the compiler has determined that the map or the first bucket // can be created on the stack, h and/or bucket may be non-nil. // If h != nil, the map can be created directly in h. // If bucket != nil, bucket can be used as the first bucket. func makemap(t *maptype, hint int64, h *hmap, bucket unsafe.Pointer) *hmap
As you see, the type of the value returned from runtime.makemap is a pointer to a runtime.hmap structure. We cannot see this from normal Go code, but we can confirm that a map value is the same size as a uintptr–one machine word.
package main
import (
"fmt"
"unsafe"
)
func main() {
var m map[int]int
var p uintptr
fmt.Println(unsafe.Sizeof(m), unsafe.Sizeof(p)) // 8 8 (linux/amd64)
}
If maps are pointers, shouldn’t they be *map[key]value?
It’s a good question that if maps are pointer values, why does the expression make(map[int]int) return a value with the type map[int]int. Shouldn’t it return a *map[int]int? Ian Taylor answered this recently in a golang-nuts thread1.
In the very early days what we call maps now were written as pointers, so you wrote *map[int]int. We moved away from that when we realized that no one ever wrote `map` without writing `*map`.
Arguably renaming the type from *map[int]int to map[int]int, while confusing because the type does not look like a pointer, was less confusing than a pointer shaped value which cannot be dereferenced.
Conclusion
Maps, like channels, but unlike slices, are just pointers to runtime types. As you saw above, a map is just a pointer to a runtime.hmap structure.
Maps have the same pointer semantics as any other pointer value in a Go program. There is no magic save the rewriting of map syntax by the compiler into calls to functions in runtime/hmap.go.
Notes
- If you look far enough back in the history of Go repository, you can find examples of maps created with the new operator.