Anthony Starks has remixed my original Google Present based slides using his fantastic Deck presentation tool. You can check out his remix over on his blog, mindchunk.blogspot.com.au/2014/06/remixing-with-deck.
I was recently invited to give a talk at Gocon, a fantastic Go conference held semi-annually in Tokyo, Japan. Gocon 2014 was an entirely community-run one day event combining training and an afternoon of presentations surrounding the theme of Go in production
.
The following is the text of my presentation. The original text was structured to force me to speak slowly and clearly, so I have taken the liberty of editing it slightly to be more readable.
I want to thank Bill Kennedy, Minux Ma, and especially Josh Bleecher Snyder, for their assistance in preparing this talk.
Good afternoon.
My name is David.
I am delighted to be here at Gocon today. I have wanted to come to this conference for two years and I am very grateful to the organisers for extending me the opportunity to present to you today.

I want to begin my talk with a question.
Why are people choosing to use Go ?
When people talk about their decision to learn Go, or use it in their product, they have a variety of answers, but there always three that are at the top of their list

These are the top three.
The first, Concurrency.
Go’s concurrency primitives are attractive to programmers who come from single threaded scripting languages like Nodejs, Ruby, or Python, or from languages like C++ or Java with their heavyweight threading model.
Ease of deployment.
We have heard today from experienced Gophers who appreciate the simplicity of deploying Go applications.
This leaves Performance.
I believe an important reason why people choose to use Go is because it is fast.

For my talk today I want to discuss five features that contribute to Go’s performance.
I will also share with you the details of how Go implements these features.

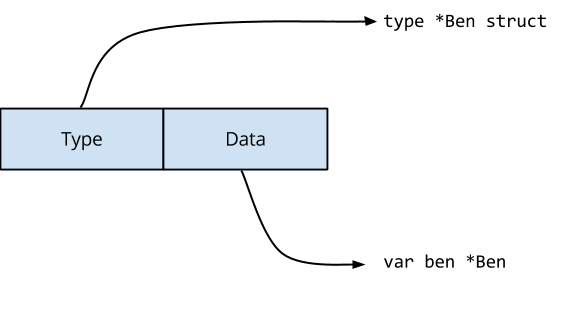
The first feature I want to talk about is Go’s efficient treatment and storage of values.

This is an example of a value in Go. When compiled, gocon consumes exactly four bytes of memory.
Let’s compare Go with some other languages

Due to the overhead of the way Python represents variables, storing the same value using Python consumes six times more memory.
This extra memory is used by Python to track type information, do reference counting, etc
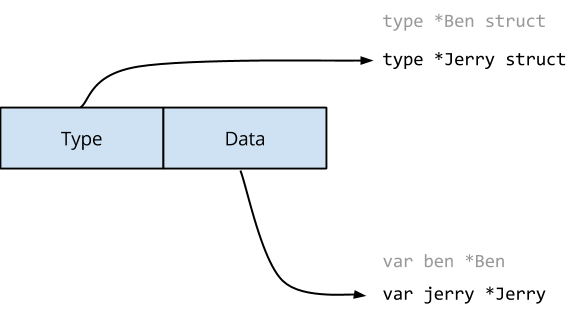
Let’s look at another example:

Similar to Go, the Java int type consumes 4 bytes of memory to store this value.
However, to use this value in a collection like a List or Map, the compiler must convert it into an Integer object.

So an integer in Java frequently looks more like this and consumes between 16 and 24 bytes of memory.
Why is this important ? Memory is cheap and plentiful, why should this overhead matter ?
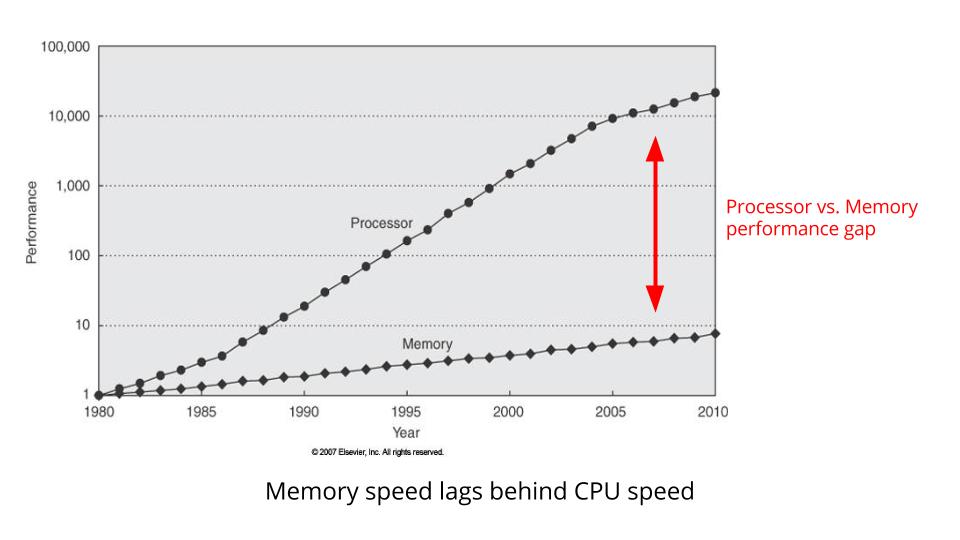
This is a graph showing CPU clock speed vs memory bus speed.
Notice how the gap between CPU clock speed and memory bus speed continues to widen.
The difference between the two is effectively how much time the CPU spends waiting for memory.

Since the late 1960’s CPU designers have understood this problem.
Their solution is a cache, an area of smaller, faster memory which is inserted between the CPU and main memory.

This is a Location type which holds the location of some object in three dimensional space. It is written in Go, so each Location consumes exactly 24 bytes of storage.
We can use this type to construct an array type of 1,000 Locations, which consumes exactly 24,000 bytes of memory.
Inside the array, the Location structures are stored sequentially, rather than as pointers to 1,000 Location structures stored randomly.
This is important because now all 1,000 Location structures are in the cache in sequence, packed tightly together.

Go lets you create compact data structures, avoiding unnecessary indirection.
Compact data structures utilise the cache better.
Better cache utilisation leads to better performance.

Function calls are not free.

Three things happen when a function is called.
A new stack frame is created, and the details of the caller recorded.
Any registers which may be overwritten during the function call are saved to the stack.
The processor computes the address of the function and executes a branch to that new address.

Because function calls are very common operations, CPU designers have worked hard to optimise this procedure, but they cannot eliminate the overhead.
Depending on what the function does, this overhead may be trivial or significant.
A solution to reducing function call overhead is an optimisation technique called Inlining.

The Go compiler inlines a function by treating the body of the function as if it were part of the caller.
Inlining has a cost; it increases binary size.
It only makes sense to inline when the overhead of calling a function is large relative to the work the function does, so only simple functions are candidates for inlining.
Complicated functions are usually not dominated by the overhead of calling them and are therefore not inlined.

This example shows the function Double calling util.Max.
To reduce the overhead of the call to util.Max, the compiler can inline util.Max into Double, resulting in something like this

After inlining there is no longer a call to util.Max, but the behaviour of Double is unchanged.
Inlining isn’t exclusive to Go. Almost every compiled or JITed language performs this optimisation. But how does inlining in Go work?
The Go implementation is very simple. When a package is compiled, any small function that is suitable for inlining is marked and then compiled as usual.
Then both the source of the function and the compiled version are stored.

This slide shows the contents of util.a. The source has been transformed a little to make it easier for the compiler to process quickly.
When the compiler compiles Double it sees that util.Max is inlinable, and the source of util.Max is available.
Rather than insert a call to the compiled version of util.Max, it can substitute the source of the original function.
Having the source of the function enables other optimizations.

In this example, although the function Test always returns false, Expensive cannot know that without executing it.
When Test is inlined, we get something like this

The compiler now knows that the expensive code is unreachable.
Not only does this save the cost of calling Test, it saves compiling or running any of the expensive code that is now unreachable.
The Go compiler can automatically inline functions across files and even across packages. This includes code that calls inlinable functions from the standard library.

Mandatory garbage collection makes Go a simpler and safer language.
This does not imply that garbage collection makes Go slow, or that garbage collection is the ultimate arbiter of the speed of your program.
What it does mean is memory allocated on the heap comes at a cost. It is a debt that costs CPU time every time the GC runs until that memory is freed.

There is however another place to allocate memory, and that is the stack.
Unlike C, which forces you to choose if a value will be stored on the heap, via malloc, or on the stack, by declaring it inside the scope of the function, Go implements an optimisation called escape analysis.

Escape analysis determines whether any references to a value escape the function in which the value is declared.
If no references escape, the value may be safely stored on the stack.
Values stored on the stack do not need to be allocated or freed.
Lets look at some examples

Sum adds the numbers between 1 and 100 and returns the result. This is a rather unusual way to do this, but it illustrates how Escape Analysis works.
Because the numbers slice is only referenced inside Sum, the compiler will arrange to store the 100 integers for that slice on the stack, rather than the heap.
There is no need to garbage collect numbers, it is automatically freed when Sum returns.

This second example is also a little contrived. In CenterCursor we create a new Cursor and store a pointer to it in c.
Then we pass c to the Center() function which moves the Cursor to the center of the screen.
Then finally we print the X and Y locations of that Cursor.
Even though c was allocated with the new function, it will not be stored on the heap, because no reference c escapes the CenterCursor function.

Go’s optimisations are always enabled by default. You can see the compiler’s escape analysis and inlining decisions with the -gcflags=-m switch.
Because escape analysis is performed at compile time, not run time, stack allocation will always be faster than heap allocation, no matter how efficient your garbage collector is.
I will talk more about the stack in the remaining sections of this talk.

Go has goroutines. These are the foundations for concurrency in Go.
I want to step back for a moment and explore the history that leads us to goroutines.
In the beginning computers ran one process at a time. Then in the 60’s the idea of multiprocessing, or time sharing became popular.
In a time-sharing system the operating systems must constantly switch the attention of the CPU between these processes by recording the state of the current process, then restoring the state of another.
This is called process switching.

There are three main costs of a process switch.
First is the kernel needs to store the contents of all the CPU registers for that process, then restore the values for another process.
The kernel also needs to flush the CPU’s mappings from virtual memory to physical memory as these are only valid for the current process.
Finally there is the cost of the operating system context switch, and the overhead of the scheduler function to choose the next process to occupy the CPU.

There are a surprising number of registers in a modern processor. I have difficulty fitting them on one slide, which should give you a clue how much time it takes to save and restore them.
Because a process switch can occur at any point in a process’ execution, the operating system needs to store the contents of all of these registers because it does not know which are currently in use.

This lead to the development of threads, which are conceptually the same as processes, but share the same memory space.
As threads share address space, they are lighter than processes so are faster to create and faster to switch between.

Goroutines take the idea of threads a step further.
Goroutines are cooperatively scheduled, rather than relying on the kernel to manage their time sharing.
The switch between goroutines only happens at well defined points, when an explicit call is made to the Go runtime scheduler.
The compiler knows the registers which are in use and saves them automatically.

While goroutines are cooperatively scheduled, this scheduling is handled for you by the runtime.
Places where Goroutines may yield to others are:
- Channel send and receive operations, if those operations would block.
- The Go statement, although there is no guarantee that new goroutine will be scheduled immediately.
- Blocking syscalls like file and network operations.
- After being stopped for a garbage collection cycle.
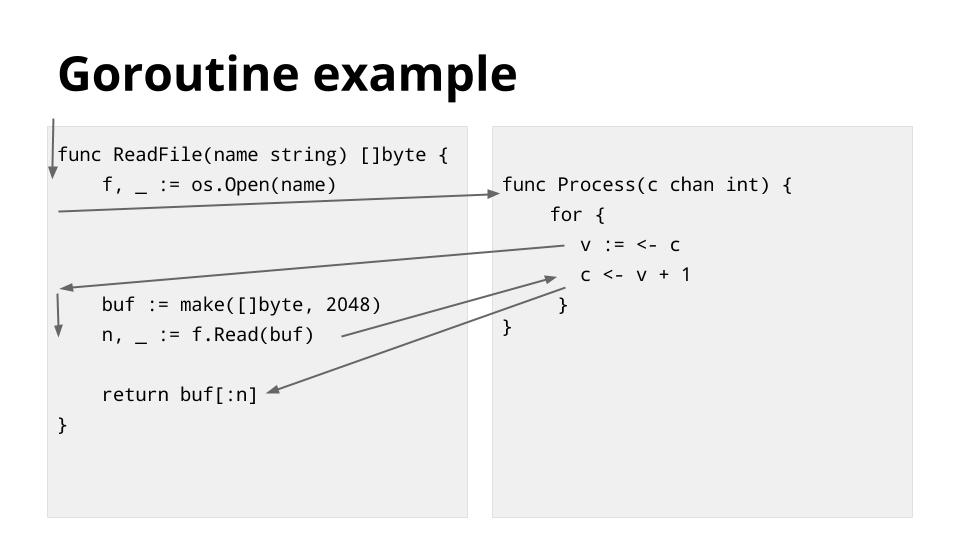
This an example to illustrate some of the scheduling points described in the previous slide.
The thread, depicted by the arrow, starts on the left in the ReadFile function. It encounters os.Open, which blocks the thread while waiting for the file operation to complete, so the scheduler switches the thread to the goroutine on the right hand side.
Execution continues until the read from the c chan blocks, and by this time the os.Open call has completed so the scheduler switches the thread back the left hand side and continues to the file.Read function, which again blocks on file IO.
The scheduler switches the thread back to the right hand side for another channel operation, which has unblocked during the time the left hand side was running, but it blocks again on the channel send.
Finally the thread switches back to the left hand side as the Read operation has completed and data is available.

This slide shows the low level runtime.Syscall function which is the base for all functions in the os package.
Any time your code results in a call to the operating system, it will go through this function.
The call to entersyscall informs the runtime that this thread is about to block.
This allows the runtime to spin up a new thread which will service other goroutines while this current thread blocked.
This results in relatively few operating system threads per Go process, with the Go runtime taking care of assigning a runnable Goroutine to a free operating system thread.

In the previous section I discussed how goroutines reduce the overhead of managing many, sometimes hundreds of thousands of concurrent threads of execution.
There is another side to the goroutine story, and that is stack management, which leads me to my final topic.
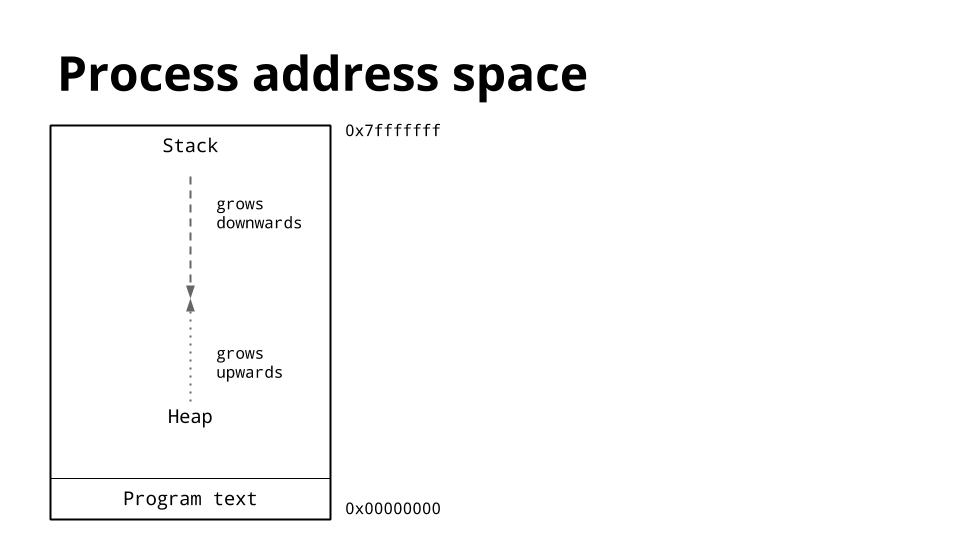
This is a diagram of the memory layout of a process. The key thing we are interested is the location of the heap and the stack.
Traditionally inside the address space of a process, the heap is at the bottom of memory, just above the program (text) and grows upwards.
The stack is located at the top of the virtual address space, and grows downwards.
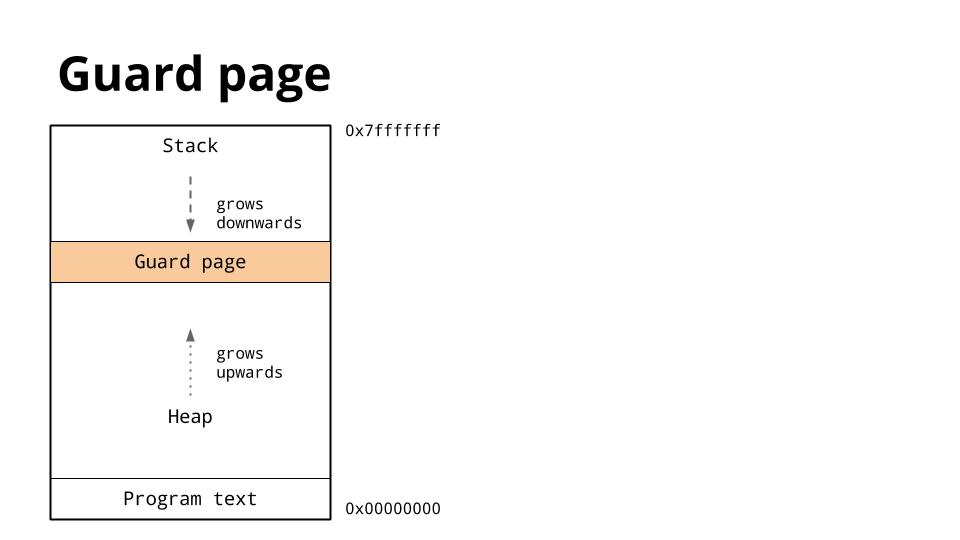
Because the heap and stack overwriting each other would be catastrophic, the operating system usually arranges to place an area of unwritable memory between the stack and the heap to ensure that if they did collide, the program will abort.
This is called a guard page, and effectively limits the stack size of a process, usually in the order of several megabytes.
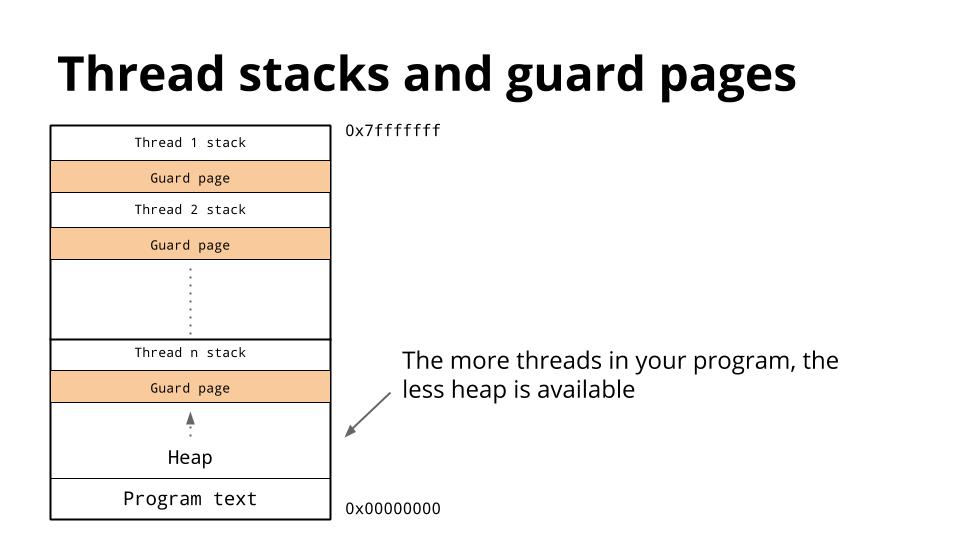
We’ve discussed that threads share the same address space, so for each thread, it must have its own stack.
Because it is hard to predict the stack requirements of a particular thread, a large amount of memory is reserved for each thread’s stack along with a guard page.
The hope is that this is more than will ever be needed and the guard page will never be hit.
The downside is that as the number of threads in your program increases, the amount of available address space is reduced.

We’ve seen that the Go runtime schedules a large number of goroutines onto a small number of threads, but what about the stack requirements of those goroutines ?
Instead of using guard pages, the Go compiler inserts a check as part of every function call to check if there is sufficient stack for the function to run. If there is not, the runtime can allocate more stack space.
Because of this check, a goroutines initial stack can be made much smaller, which in turn permits Go programmers to treat goroutines as cheap resources.
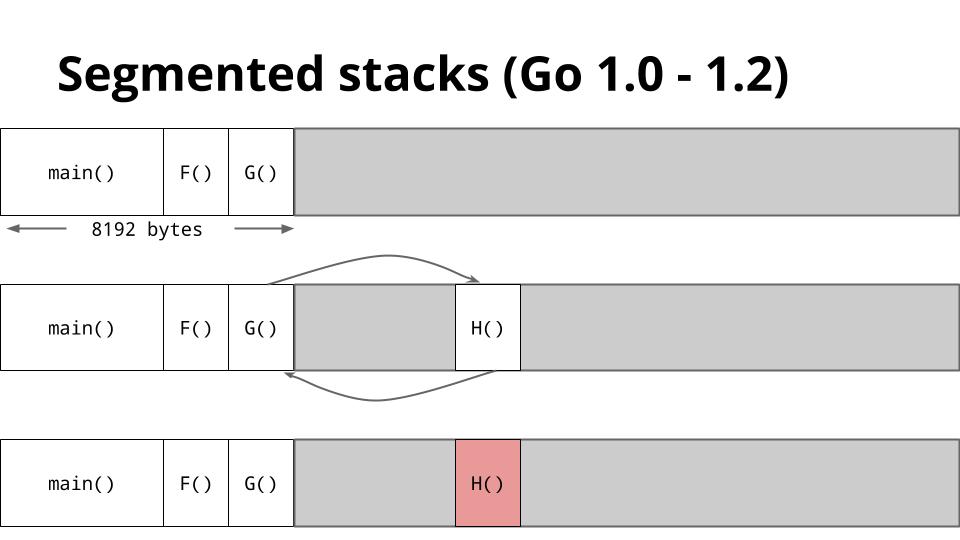
This is a slide that shows how stacks are managed in Go 1.2.
When G calls to H there is not enough space for H to run, so the runtime allocates a new stack frame from the heap, then runs H on that new stack segment. When H returns, the stack area is returned to the heap before returning to G.
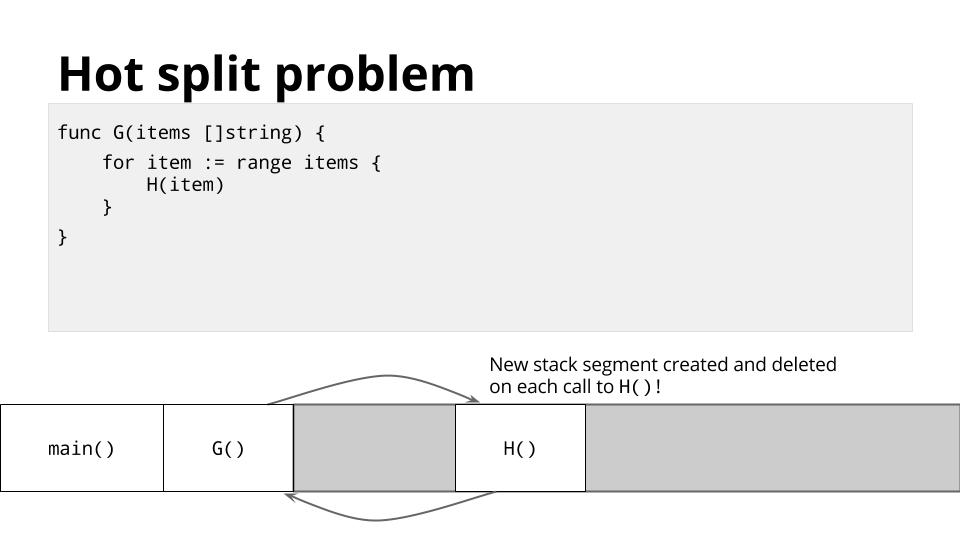
This method of managing the stack works well in general, but for certain types of code, usually recursive code, it can cause the inner loop of your program to straddle one of these stack boundaries.
For example, in the inner loop of your program, function G may call H many times in a loop,
Each time this will cause a stack split. This is known as the hot split problem.
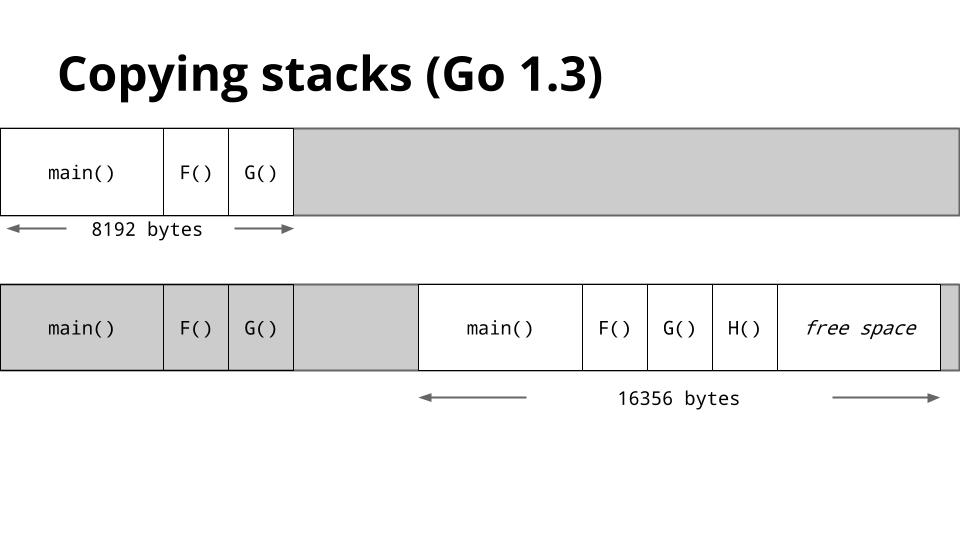
To solve hot splits, Go 1.3 has adopted a new stack management method.
Instead of adding and removing additional stack segments, if the stack of a goroutine is too small, a new, larger, stack will be allocated.
The old stack’s contents are copied to the new stack, then the goroutine continues with its new larger stack.
After the first call to H the stack will be large enough that the check for available stack space will always succeed.
This resolves the hot split problem.

Values, Inlining, Escape Analysis, Goroutines, and segmented/copying stacks.
These are the five features that I chose to speak about today, but they are by no means the only things that makes Go a fast programming language, just as there more that three reasons that people cite as their reason to learn Go.
As powerful as these five features are individually, they do not exist in isolation.
For example, the way the runtime multiplexes goroutines onto threads would not be nearly as efficient without growable stacks.
Inlining reduces the cost of the stack size check by combining smaller functions into larger ones.
Escape analysis reduces the pressure on the garbage collector by automatically moving allocations from the heap to the stack.
Escape analysis is also provides better cache locality.
Without growable stacks, escape analysis might place too much pressure on the stack.

* Thank you to the Gocon organisers for permitting me to speak today
* twitter / web / email details
* thanks to @offbymany, @billkennedy_go, and Minux for their assistance in preparing this talk.