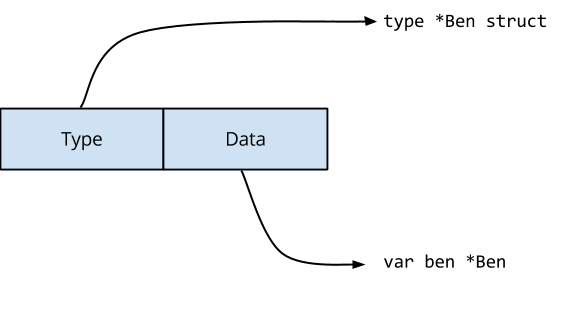
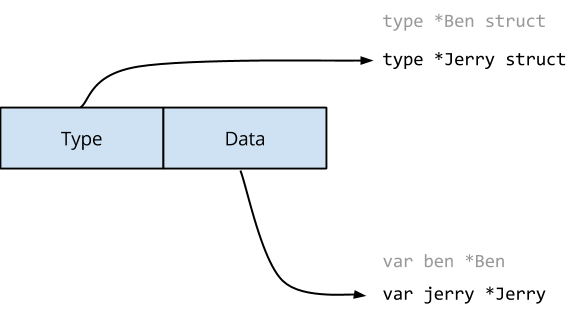
This is a post inspired by a question on the Go Forum. The question, paraphrased, was “If properly aligned writes are guaranteed to be atomic by the processor, why does the race detector complain?”
The answer is, there are two uses of the word atomic in play here. The first, the one the OP references, is a property of most microprocessors that, as long as the address of the write is naturally aligned–if it’s a 32-bit value, say, then it is always written to an address which is a multiple of four–then nothing will observe a half written value.
To explain what that means, consider the opposite, an unaligned write where a 32-bit value is written to an address whose bottom two bits are not zero. In this case the processor has to split the write into two, spanning the boundary. This is known as a torn write as an observer on the bus could see this partially updated value.1
These words comes from a time before multiple processors were common. At that time the observers of a torn read or write would most likely be other agents on the ISA, VESA, or PCI bus like disk controllers or video cards. However, we now live in the multi-core age so we need to talk about caches and visibility.
Since almost the beginning of computing, the CPU has run faster than main memory. That is to say, the performance of a computer is strongly related to the performance of its memory. This is known as the processor/memory gap. To bridge this gap processors have adopted caches which store recently accessed memory in a small, fast, store, closer to the processor.2 Because caches also buffer writes back to main memory, while the property that an aligned address will be atomic remains, when that write occurs has become less deterministic.3 This is the domain of second use of the word atomic, the one implemented by the sync/atomic package.
In a modern multiprocessor system, a write to main memory will be buffered in multiple levels of caches before hitting main memory. This is done to to hide the latency of main memory, but in doing so it means that communicating between processors using main memory is now imprecise; a value read from memory may have already been overwritten by one processor, however the new value has not made its way through the various caches yet.
To solve this ambiguity you need to use a memory fence, also known as a memory barrier. A memory write barrier operation tells the processor that it has to wait until all the outstanding operations in its pipeline, specifically writes, have been flushed to main memory. This operation also invalidates the caches
4held by other processors, forcing them to retrieve the new value directly from memory. The same is true for reads, you use a memory read barrier to tell the processor to stop and synchronise with any outstanding writes to memory.
In terms of Go, read and write memory barrier operations are handled by the sync/atomic package, specifically the family of atomic.Load and atomic.Store functions respectively.
In answer to the OP’s question: to safely use a value in memory as a communication channel between two goroutines, the race detector will complain unless the sync/atomic package is used.