This article is also available in Japanese, イベントループなしでのハイパフォーマンス – C10K問題へのGoの回答
This article is based on a presentation I gave earlier this year at OSCON. It has been edited for brevity and to address some of the points of feedback I received after the talk.
A common refrain when talking about Go is it’s a language that works well on the server; static binaries, powerful concurrency, and high performance.
This article focuses on the last two items, how the language and the runtime transparently let Go programmers write highly scalable network servers, without having to worry about thread management or blocking I/O.
An argument for an efficient programming language
But before I launch into the technical discussion, I want to make two arguments to illustrate the market that Go targets.
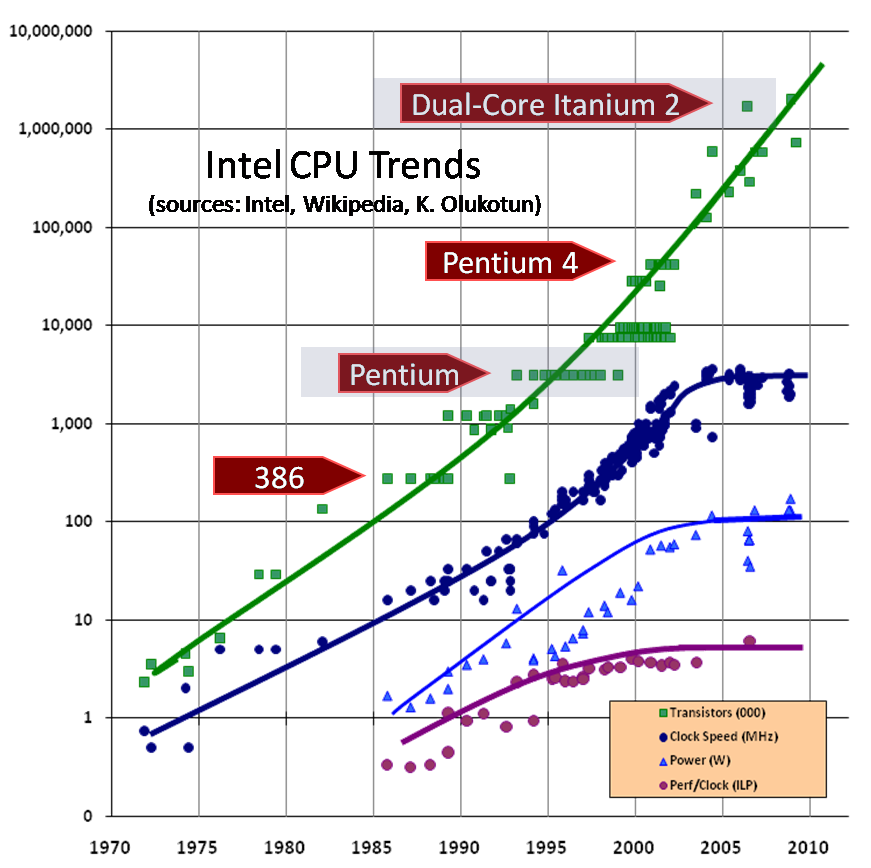
Moore’s Law
The oft mis quoted Moore’s law states that the number of transistors per square inch doubles roughly every 18 months.
However clock speeds, which are a function of entirely different properties, topped out a decade ago with the Pentium 4 and have been slipping backwards ever since.
From space constrained to power constrained

Sun Enterprise e450—about the size of a bar fridge, about the same power consumption. Image credit: eBay
This is the Sun e450. When I started my career, these were the workhorses of the industry.
These things were massive. Three of them, stacked one on top of another would consume an entire 19″ Rack. They only consumed about 500 Watts each.
Over the last decade, data centres have moved from space constrained, to power constrained. The last two data centre rollouts I was involved in, we ran out of power when the rack was barely 1/3rd full.
Because compute densities have improved so rapidly, data centre space is no longer a problem. However, modern servers consume significantly more power, in a much smaller area, making cooling harder yet at the same time critical.
Being power constrained has effects at the macro level—you can’t get enough power for a rack of 1200 Watt 1RU servers—and at the micro level, all this power, hundreds of watts, is being dissipated in a tiny silicon die.
Where does this power consumption come from ?
This is an inverter, one of the simplest logic gates possible. If the input, A, is high, then the output, Q, will be low, and vice versa.
All today’s consumer electronics are built with CMOS logic. CMOS stands for Complementary Metal Oxide Semiconductor. The complementary part is the key. Each logic element inside the CPU is implemented with a pair of transistors, as one switches on, another switches off.
When the circuit is on or off, no current flows directly from the source to the drain. However, during transition there is a brief period where both transistors are conducting, creating a direct short.
Power consumption, and thus heat dissipation, is directly proportional to number of transition per second—the cpu clock speed1.
CPU feature size reductions are primarily aimed at reducing power consumption. Reducing power consumption doesn’t just mean “green”. The primary goal is to keep power consumption, and thus heat dissipation, below levels that will damage the CPU.
With clock speeds falling, and in direct conflict with power consumption, performance improvements come mainly from microarchitecture tweaks and esoteric vector instructions, which are not directly useful for the general computation. Added up, each microarchitecture (5 year cycle) change yields at most 10% improvement per generation, and more recently barely 4-6%.
“The free lunch is over”
Hopefully it is clear to you now that hardware is not getting any faster. If performance and scale are important to you, then you’ll agree with me that the days of throwing hardware at the problem are over, at least in the conventional sense. As Herb Sutter put it “The free lunch is over”.
You need a language which is efficient, because inefficient languages just do not justify themselves in production, at scale, on a capital expenditure basis.
An argument for a concurrent programming language
My second argument follows from my first. CPUs are not getting faster, but they are getting wider. This is where the transistors are going and it shouldn’t be a great surprise.

Image credit: Intel
Simultaneous multithreading, or as Intel calls it hyper threading allows a single core to execute multiple instruction streams in parallel with the addition of a modest amount of hardware. Intel uses hyper threading to artificially segment the market for processors, Oracle and Fujitsu apply hyper threading more aggressively to their products using 8 or 16 hardware threads per core.
Dual socket has been a reality since the late 1990s with the Pentium Pro and is now mainstream with most servers supporting dual or quad socket designs. Increasing transistor counts have allowed the entire CPU to be co-located with siblings on the same chip. Dual core on mobile parts, quad core on desktop parts, even more cores on server parts are now the reality. You can buy effectively as many cores in a server as your budget will allow.
And to take advantage of these additional cores, you need a language with a solid concurrency story.
Processes, threads and goroutines
Go has goroutines which are the foundation for its concurrency story. I want to step back for a moment and explore the history that leads us to goroutines.
Processes
In the beginning, computers ran one job at a time in a batch processing model. In the 60’s a desire for more interactive forms of computing lead to the development of multiprocessing, or time sharing, operating systems. By the 70’s this idea was well established for network servers, ftp, telnet, rlogin, and later Tim Burners-Lee’s CERN httpd, handled each incoming network connections by forking a child process.
In a time-sharing system, the operating systems maintains the illusion of concurrency by rapidly switching the attention of the CPU between active processes by recording the state of the current process, then restoring the state of another. This is called context switching.
Context switching

Image credit: Immae (CC BY-SA 3.0)
There are three main costs of a context switch.
- The kernel needs to store the contents of all the CPU registers for that process, then restore the values for another process. Because a process switch can occur at any point in a process’ execution, the operating system needs to store the contents of all of these registers because it does not know which are currently in use 2.
- The kernel needs to flush the CPU’s virtual address to physical address mappings (TLB cache) 3.
- Overhead of the operating system context switch, and the overhead of the scheduler function to choose the next process to occupy the CPU.
These costs are relatively fixed by the hardware, and depend on the amount of work done between context switches to amortise their cost—rapid context switching tends to overwhelm the amount of work done between context switches.
Threads
This lead to the development of threads, which are conceptually the same as processes, but share the same memory space. As threads share address space, they are lighter to schedule than processes, so are faster to create and faster to switch between.
Threads still have an expensive context switch cost; a lot of state must be retained. Goroutines take the idea of threads a step further.
Goroutines
Rather than relying on the kernel to manage their time sharing, goroutines are cooperatively scheduled. The switch between goroutines only happens at well defined points, when an explicit call is made to the Go runtime scheduler. The major points where a goroutine will yield to the scheduler include:
- Channel send and receive operations, if those operations would block.
- The go statement, although there is no guarantee that new goroutine will be scheduled immediately.
- Blocking syscalls like file and network operations.
- After being stopped for a garbage collection cycle.
In other words, places where the goroutine cannot continue until it has more data, or more space to put data.
Many goroutines are multiplexed onto a single operating system thread by the Go runtime. This makes goroutines cheap to create and cheap to switch between. Tens of thousands of goroutines in a single process are the norm, hundreds of thousands are not unexpected.
From the point of view of the language, scheduling looks like a function call, and has the same semantics. The compiler knows the registers which are in use and saves them automatically. A thread calls into the scheduler holding a specific goroutine stack, but may return with a different goroutine stack. Compare this to threaded applications, where a thread can be preempted at any time, at any instruction.
This results in relatively few operating system threads per Go process, with the Go runtime taking care of assigning a runnable goroutine to a free operating system thread.
Stack management
In the previous section I discussed how goroutines reduce the overhead of managing many, sometimes hundreds of thousands of concurrent threads of execution. There is another side to the goroutine story, and that is stack management.
Process address space
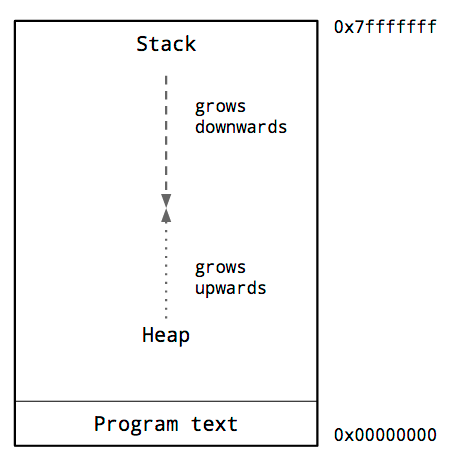 This is a diagram of the typical memory layout of a process. The key thing we are interested in is the locations of the heap and the stack.
This is a diagram of the typical memory layout of a process. The key thing we are interested in is the locations of the heap and the stack.
Inside the address space of a process, traditionally the heap is at the bottom of memory, just above the program code and grows upwards.
The stack is located at the top of the virtual address space, and grows downwards.
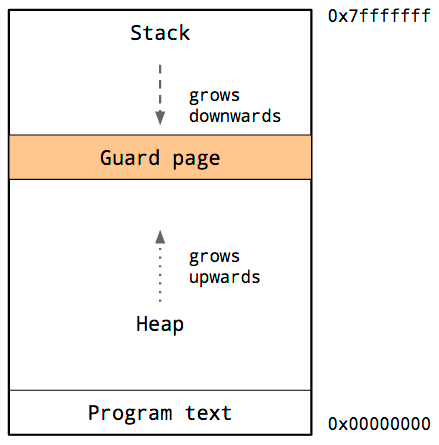 Because the heap and stack overwriting each other would be catastrophic, the operating system arranges an area of inaccessible memory between the stack and the heap.
Because the heap and stack overwriting each other would be catastrophic, the operating system arranges an area of inaccessible memory between the stack and the heap.
This is called a guard page, and effectively limits the stack size of a process, usually in the order of several megabytes.
Thread stacks
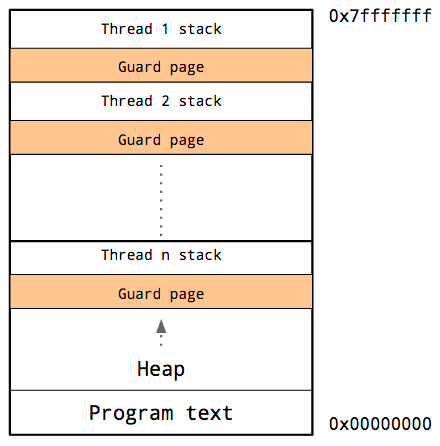 Threads share the same address space, so for each thread, it must have its own stack and its own guard page.
Threads share the same address space, so for each thread, it must have its own stack and its own guard page.
Because it is hard to predict the stack requirements of a particular thread, a large amount of memory must be reserved for each thread’s stack. The hope is that this will be more than needed and the guard page will never be hit.
The downside is that as the number of threads in your program increases, the amount of available address space is reduced.
Goroutine stack management
The early process model allowed the programmer to view the heap and the stack as large enough to not be a concern. The downside was a complicated and expensive subprocess model.
Threads improved the situation a bit, but require the programmer to guess the most appropriate stack size; too small, your program will abort, too large, you run out of virtual address space.
We’ve seen that the Go runtime schedules a large number of goroutines onto a small number of threads, but what about the stack requirements of those goroutines ?
Goroutine stack growth
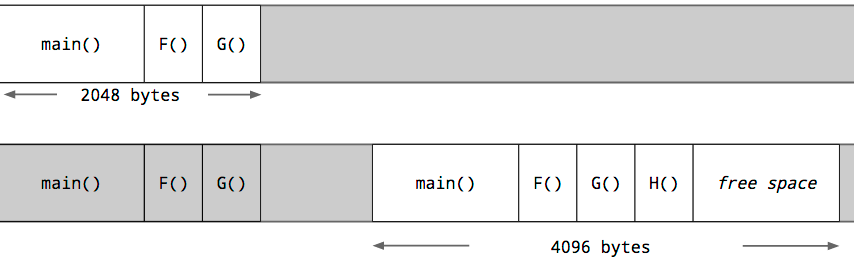 Each goroutine starts with an small stack, allocated from the heap. The size has fluctuated over time, but in Go 1.5 each goroutine starts with a 2k allocation.
Each goroutine starts with an small stack, allocated from the heap. The size has fluctuated over time, but in Go 1.5 each goroutine starts with a 2k allocation.
Instead of using guard pages, the Go compiler inserts a check as part of every function call to test if there is sufficient stack for the function to run. If there is sufficient stack space, the function runs as normal.
If there is insufficient space, the runtime will allocate a larger stack segment on the heap, copy the contents of the current stack to the new segment, free the old segment, and the function call is restarted.
Because of this check, a goroutine’s initial stack can be made much smaller, which in turn permits Go programmers to treat goroutines as cheap resources. Goroutine stacks can also shrink if a sufficient portion remains unused. This is handled during garbage collection.
Integrated network poller
In 2002 Dan Kegel published what he called the c10k problem. Simply put, how to write server software that can handle at least 10,000 TCP sessions on the commodity hardware of the day. Since that paper was written, conventional wisdom has suggested that high performance servers require native threads, or more recently, event loops.
Threads carry a high overhead in terms of scheduling cost and memory footprint. Event loops ameliorate those costs, but introduce their own requirements for a complex, callback driven style.
Go provides programmers the best of both worlds.
Go’s answer to c10k
In Go, syscalls are usually blocking operations, this includes reading and writing to file descriptors. The Go scheduler handles this by finding a free thread or spawning another to continue to service goroutines while the original thread blocks. In practice this works well for file IO as a small number of blocking threads can quickly exhaust your local IO bandwidth.
However for network sockets, by design at any one time almost all of your goroutines are going to be blocked waiting for network IO. In a naive implementation this would require as many threads as goroutines, all blocked waiting on network traffic. Go’s integrated network poller handles this efficiently due to the cooperation between the runtime and net packages.
In older versions of Go, the network poller was a single goroutine that was responsible for polling for readiness notification using kqueue or epoll. The polling goroutine would communicate back to waiting goroutines via a channel. This achieved the goal of avoiding a thread per syscall overhead, but used a generalised wakeup mechanism of channel sends. This meant the scheduler was not aware of the source or importance of the wakeup.
In current versions of Go, the network poller has been integrated into the runtime itself. As the runtime knows which goroutine is waiting for the socket to become ready it can put the goroutine back on the same CPU as soon as the packet arrives, reducing latency and increasing throughput.
Goroutines, stack management, and an integrated network poller
In conclusion, goroutines provide a powerful abstraction that free the programmer from worrying about thread pools or event loops.
The stack of a goroutine is as big as it needs to be without being concerned about sizing thread stacks or thread pools.
The integrated network poller lets Go programmers avoid convoluted callback styles while still leveraging the most efficient IO completion logic available from the operating system.
The runtime make sure that there will be just enough threads to service all your goroutines and keep your cores active.
And all of these features are transparent to the Go programmer.
Footnotes:
- CMOS power consumption is not only caused by the short circuit current when the circuit is switching. Additional power consumption comes from charging the output capacitance of the gate, and leakage current through the MOSFET gate increases as the size of the transistor decreases. You can read more about this from in a the lecture materials from CMU’s ECE322 course. Bill Herd has a published a series of articles on how CMOS works.
- This is an oversimplification. In some cases the operating system can avoid saving and restoring infrequently used architectural registers by starting the the process in a mode where access to floating point or MMX/SSE registers will cause the program to fault, thereby informing the kernel that the process will now use those registers and it should from then on save and restore them.
- Some CPUs have what is known as a tagged TLB. In the case of tagged TLB support the operating system can tell the processor to associate particular TLB cache entries with an identifier, derived from the process ID, rather than treating each cache entry as global. The upside is this avoids flushing out entries on each process switch if the process is placed back on the same CPU in short order.

{kind=link}