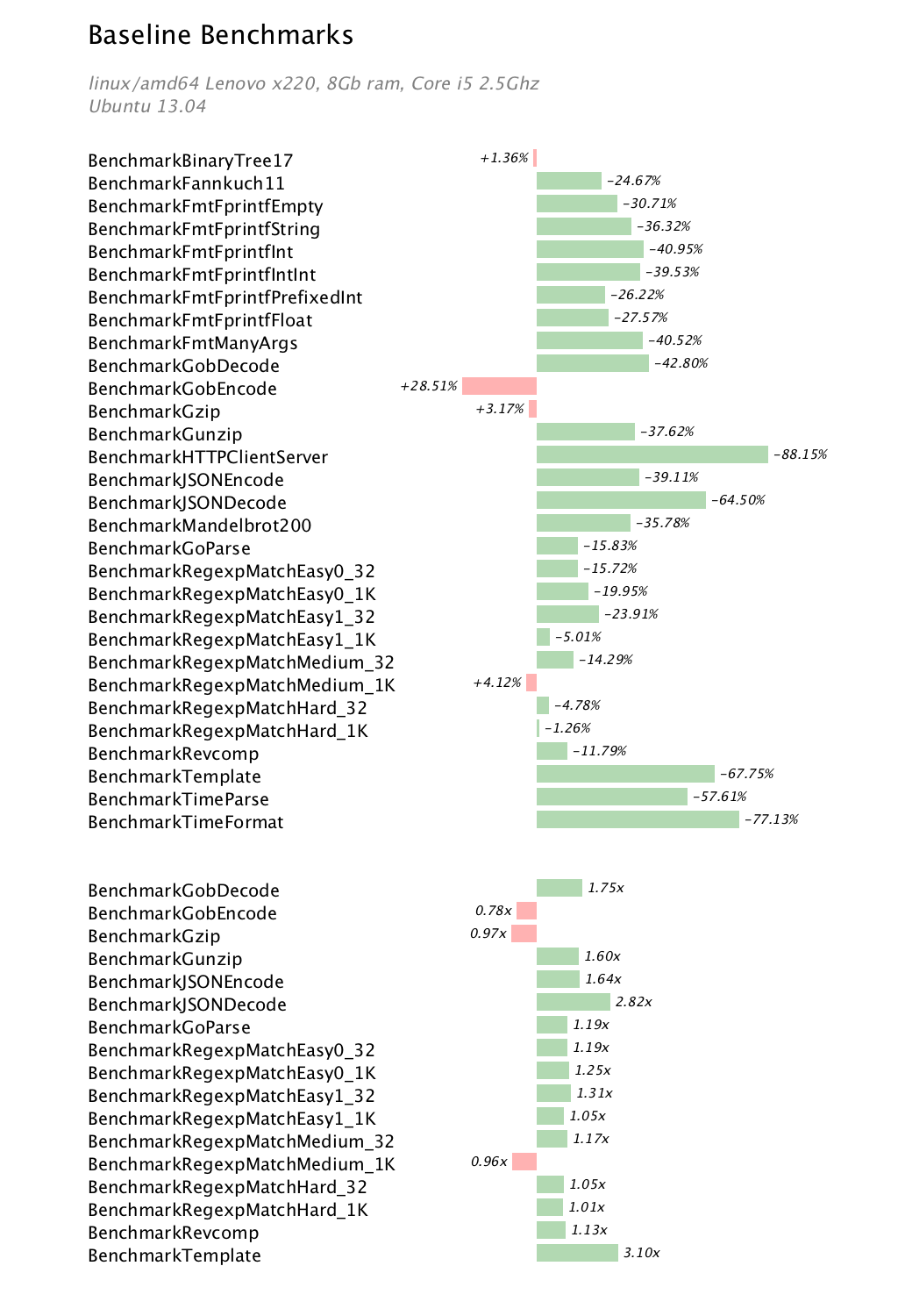
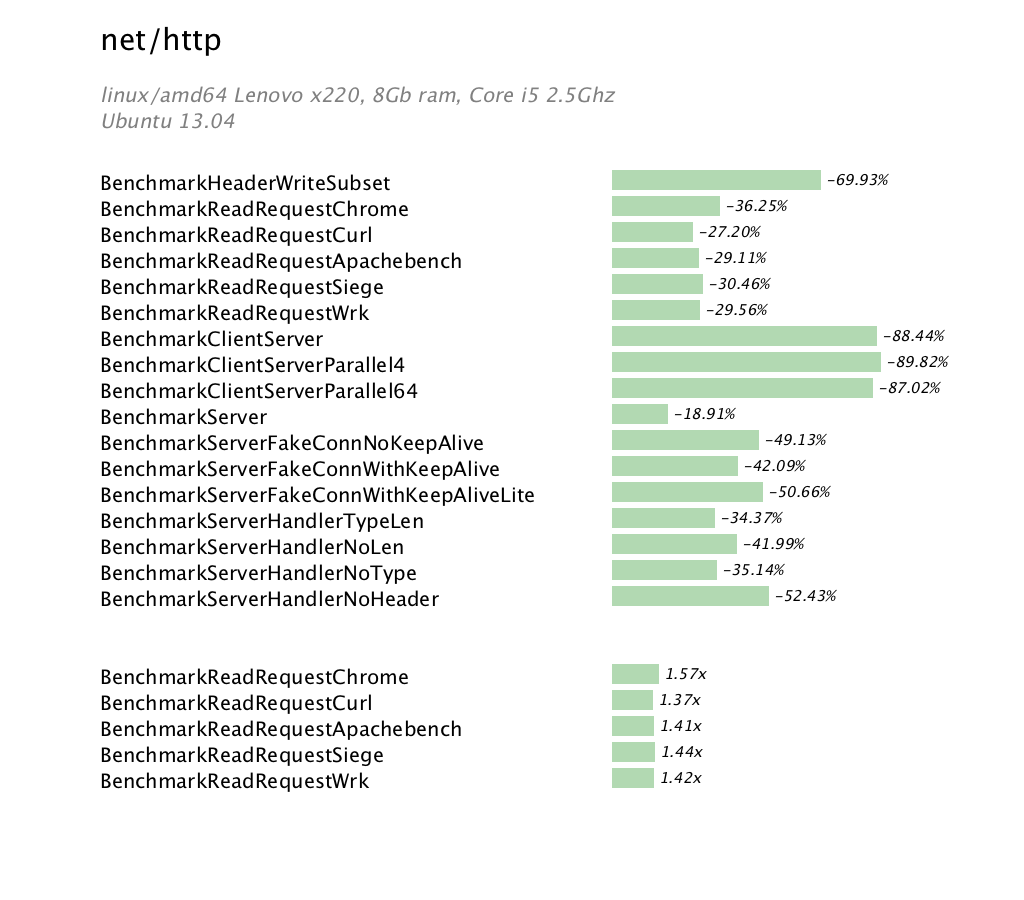
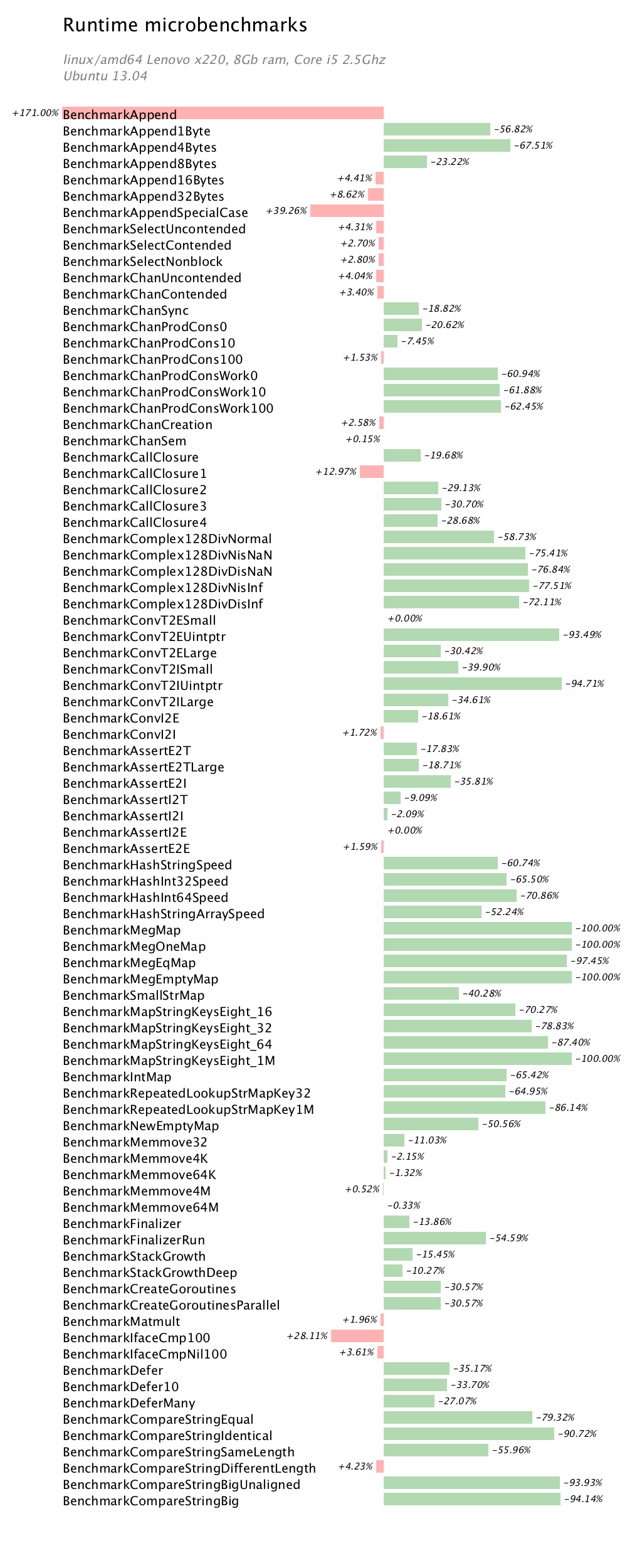
This article is intended as a short introduction to the mechanics and syntax of writing a table driven test in Go. Supporting this article is a small repository, https://github.com/davecheney/fib, which contains all the code mentioned below.
Introduction
I enjoy writing table driven tests in Go. While not unique to the language, table driven tests leverage several features, composite literals and anonymous structs, to allow you to write related tests in a compact form.
As an example, please consider the case of testing this overused function
package fib
// Fib returns the nth number in the Fibonacci series.
func Fib(n int) int {
if n < 2 {
return n
}
return Fib(n-1) + Fib(n-2)
}
The table structure
At the heart of all table driven tests is the table itself, which provides the inputs and expected results of the function under test. In most cases the table is a slice of anonymous structs, which allows the table to be written in a compact form.
var fibTests = []struct {
n int // input
expected int // expected result
}{
{1, 1},
{2, 1},
{3, 2},
{4, 3},
{5, 5},
{6, 8},
{7, 13},
}
If you wished, you could give the struct a name, in which case the table definition would look something like this
type fibTest struct {
n int
expected int
}
var fibTests = []fibTest {
{1, 1}, {2, 1}, {3, 2}, {4, 3}, {5, 5}, {6, 8}, {7, 13},
}
Hooking it up
Now that we have the table of inputs and results defined, we need to write a driver function to iterate through the inputs and compare the results to their expected value. Rather than one Test function per set of values, we can use the range clause to loop over each test case.
func TestFib(t *testing.T) {
for _, tt := range fibTests {
actual := Fib(tt.n)
if actual != tt.expected {
t.Errorf("Fib(%d): expected %d, actual %d", tt.n, tt.expected, actual)
}
}
}
In this example we range over all the fibTests defined above, assigning their value in turn to tt. We then call Fib passing in the value of tt.n and compare the result, stored in actual, with the value of tt.expected.
The use of the names actual and expected show my JUnit heritage, others may prefer names like want and got. You should choose something that works for you and gives a clear meaning in your test code.
The use of t.Errorf instead of t.Fatalf is a personal preference. As Fib is a pure function it is safe to continue the loop after a failure. I find this generally reduces test whack-a-mole by returning all the failures at once.
Conclusion
In my introduction I said that table driven tests are one my favorite parts of the Go language. They allow you to write unit tests in a concise fashion, hopefully leading to greater test coverage at a lower line count. If done correctly, adding additional test cases is as simple as a new element in the test table.
This is certainly not the only way that tests could be written in Go, nor the only way to write table driven tests. The Go standard library contains many examples of this form of testing which are worth studying. In particular I suggest the tests for the math and time packages are an excellent starting point.
At the other end of the spectrum is this table driven test of the Juju status command which defines its own language of helpers to populate the table structure. Although this elevates the table driven test to ninja levels, it still contains the same components and concepts, and right at the bottom of the file you’ll find a simple function driving each test.