This is the second in a three part series exploring the performance improvements in the recent Go 1.1 release.
In part 1 I explored the improvements on amd64 platforms, as well as general improvements available to all via runtime and compiler frontend improvements.
In this article I will focus on the performance of Go 1.1 on 386 machines. The results in this article are taken from linux-386-d5666bad617d-vs-e570c2daeaca.txt.
Go 1 benchmarks on linux/386
When it comes to performance, the 8g compiler is at a disadvantage. The small number of general purpose registers available in the 386 programming model, and the weird restrictions on their use place a heavy burden on the compiler and optimiser. However that did not stop Rémy Oudompheng making several significant contributions to 8g during the 1.1 cycle.
Firstly the odd 387 floating point model was deprecated (it’s still there if you are running very old hardware with the GO386=387 switch) in favor of SSE2 instructions.
Secondly, Rémy put significant effort into porting code generation improvements from 6g into 8g (and 5g, the arm compiler). Where possible code was moved into the compiler frontend, gc, including introducing a framework to rewrite division as simpler shift and multiply operations.
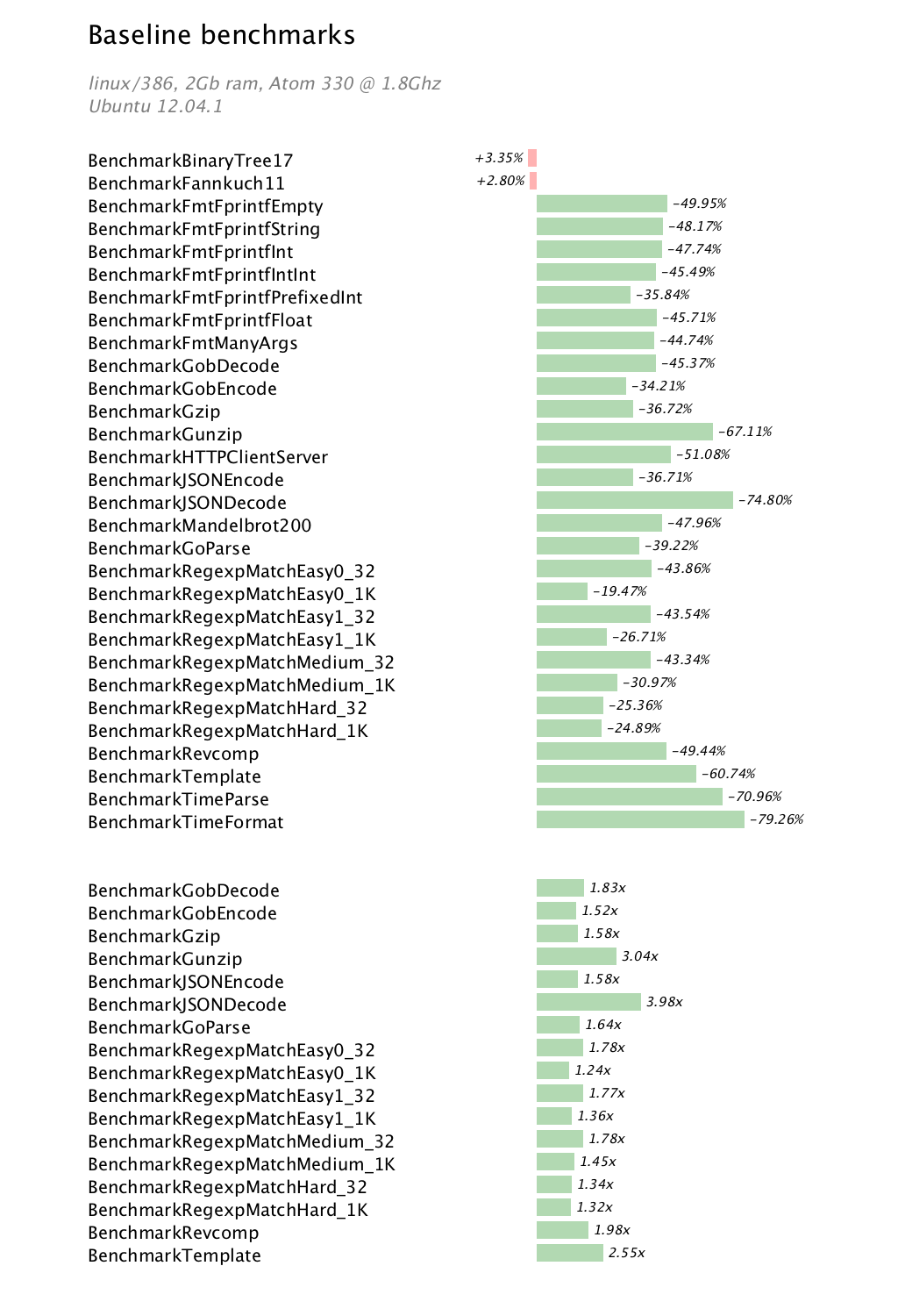
In general the results for linux/386 on this host show improvements that are as good, or in some cases, better than linux/amd64. Unlike linux/amd64, there is no slowdown in the Gzip or Gob benchmarks.
The two small regressions, BinaryTree17 and Fannkuch11, are assumed to be attributable to the garbage collector becoming more precise. This involves some additional bookkeeping to track the size and type of objects allocated on the heap, which shows up in these benchmarks.
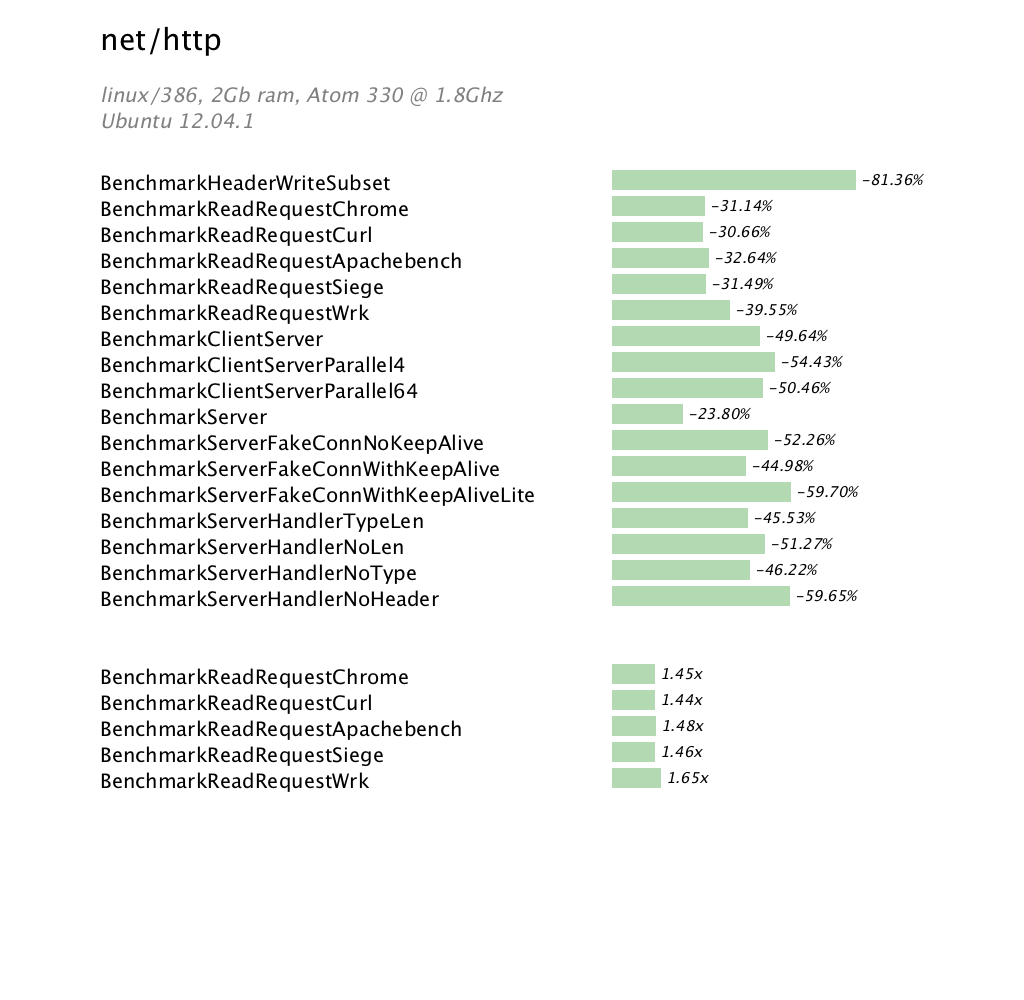
net/http benchmarks
The improvements in the net package previously demonstrated in the linux/amd64 article carry over to linux/386. The improvements in the ClientServer benchmarks are not as marked as its amd64 cousin, but nonetheless show a significant improvement overall due to the tighter integration between the runtime and net package.
Runtime microbenchmarks
Like the amd64 benchmarks in part 1, the runtime microbenchmarks show a mixture of results. Some low level operations got a bit slower, while other operations, like map have improved significantly.
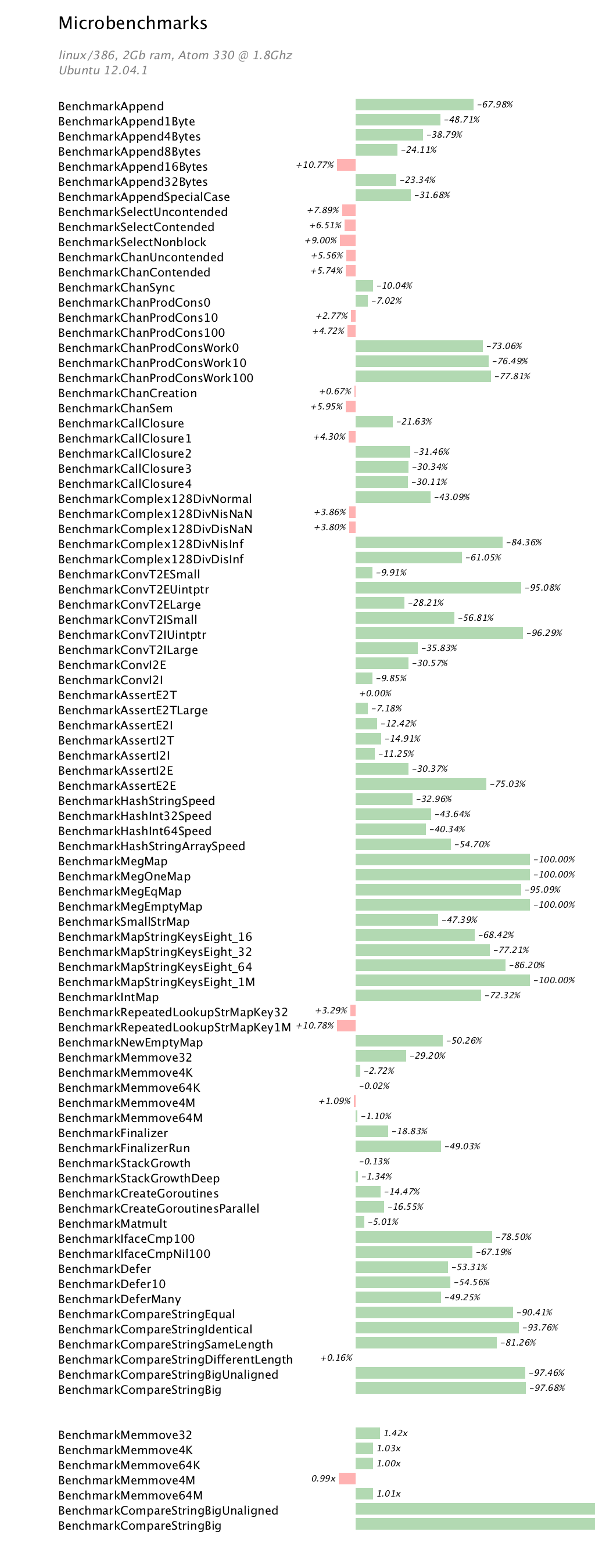
The final two benchmarks, which appear truncated, are actually so large they do not fit on the screen. The improvement is mostly due to this change which introduced a faster low level Equals operation for the strings, bytes and runtime packages. The results speak for themselves.
benchmark old MB/s new MB/s speedup BenchmarkCompareStringBigUnaligned 29.08 1145.48 39.39x BenchmarkCompareStringBig 29.09 1253.48 43.09x
Conclusion
Although 8g is not the leading compiler of the gc suite, Ken Thompson himself has said that there are essentially no free registers available on 386, linux/386 shows that it easily meets the 30-40% performance improvement claim. In some benchmarks, compared to Go 1.0, linux/386 beats linux/amd64.
Additionally, due to reductions in memory usage, all the compilers now use around half as much memory when compiling, and as a direct consequence, compile up to 30% faster than their 1.0 predecessors.
I encourage you to review the benchmark data in the autobench repository and if you are able, submit your own results.
In the final article in this series I will investigate the performance improvement Go 1.1 brings to arm platforms. I assure you, I’ve saved the best til last.
Update: thanks to @ajstarks who provided me with higher quality benchviz images.
This is a superb article, my fine gentleman! SUPERB!
Go is truly reaching the BIG LEAGUES now. It is playing with the BIGGEST OF THE BIG BOYS.
Performance improvements like you’ve described are what separates the WHEAT from the CHAFF.
Go is clearly now becoming the WHEAT.
No longer do we think merely of C, C++ and Java when developing real software. We now think of Go, and Go alone. If there is heavy lifting to be done, and it needs to be done right, then it is clear that Go is THE RIGHT CHOICE.
From one man to another, many thanks,
Ryan
“The two small regressions, BinaryTree17 and Fannkuch11, are assumed to be attributable to the garbage collector becoming more precise. This involves some additional bookkeeping to track the size and type of objects allocated on the heap, which shows up in these benchmarks.”
Just a note: It isn’t just the overhead of additional bookkeeping. The new garbage collector hasn’t been well optimized yet. The older garbage collector spends much of its time in a highly optimized loop.
> The new garbage collector hasn’t been well optimized yet. The older garbage collector spends much of its time in a highly optimized loop.
Does that mean there’s (semi)-low hanging fruit in the new GC?
Pingback: Go 1.1 performance improvements | thoughts...
Wow, I don’t think I ever heard of a compiler producing faster code AND using less memory AND running quicker after an upgrade!
Great series – thanks!
I have just realized Go’s power. The simplistic language is AWESOME, love the minimalistic approach. Also, the performance is mindblowing vs. complexity of the written software. It’s easy and FAST. Less is better, truly. And obviously, thanks for the benchmarks, as they help in reducing cognitive dissonance associated with learning new programming languages.
“Wow, I don’t think I ever heard of a compiler producing faster code AND using less memory AND running quicker after an upgrade!”
Then I will kindly assume you’ve never heard of Niklaus Wirth either.
Hi there! Quick question that’s entirely off topic. Do you know how to make your site mobile friendly? My website looks weird when browsing from my iphone 4. I’m trying to find a template or plugin that
might be able to fix this problem. If you have any recommendations, please share.
Thank you!
Sorry, I’m afraid everything you see here is done by wordpress.