This is the final article in the series exploring the performance improvements available in the recent Go 1.1 release. You can also read part 1 and part 2 to get the back story for amd64 and 386.
This article focuses on the performance of arm platforms. Go 1.1 was an important release as it raised arm to a level on par with amd64 and 386 and introduced support for additional operating systems. Some highlights that Go 1.1 brings to arm are:
- Support for
cgo. - Additional of experimental support for
freebsd/armandnetbsd/arm. - Better code generation, including a now partially working peephole optimiser, better register allocator, and many small improvements to reduce code size.
- Support for ARMv6 hosts, including the Raspberry Pi.
- The
GOARMvariable is now optional, and automatically chooses its value based on the host Go is compiled on. - The memory allocator is now significantly faster due to elimination of many 64 bit instructions which were previously emulated a high cost.
- A significantly faster software division/modulo facility.
These changes were not possible without the efforts of Shenghou Ma, Rémy Oudompheng and Daniel Morsing who made enormous contributions to the compiler and runtime during the Go 1.1 development cycle.
Again, a huge debt of thanks is owed to Anthony Starks who helped prepare the benchmark data and images for this article.
Go 1 benchmarks on linux/arm
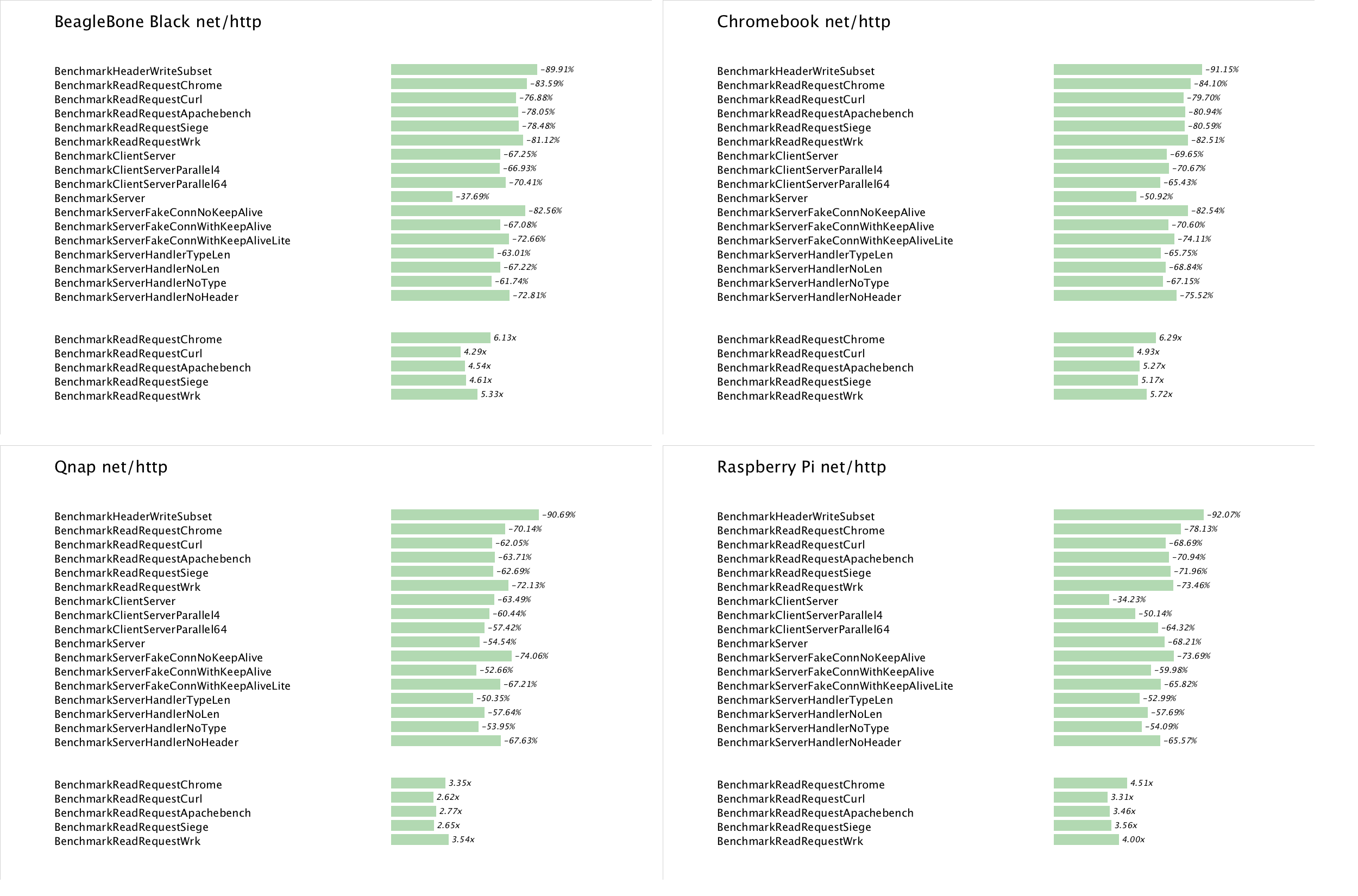
Since its release Go has supported more that one flavor of arm architecture. Presented here are benchmarks from a wide array of hosts to give a representative sample of the performance of Go 1.1 programs on arm hosts. From top left to bottom right
- Beaglebone Black, Texas Instruments AM335x Cortex-A8 ARMv7
- Samsung Chromebook, Samsung Exynos 5250 Dual Cortex-A15 ARMv7
- QNAP TS-119P, Marvell Kirkwood ARMv5
- Raspberry Pi Model B, Broadcom 2835 ARMv6
As always the results presented here are available in the autobench repository. The thumbnails are clickable for a full resolution view.
Hey, the images don’t work on my iSteve! Yup, it looks like iOS devices have a limit for the size of images they will load inside a web page, and these images are on the sadface side of that limit. If you click on the broken image, you’ll find the images will load fine in a separate page. Sorry for the inconvenience.

The speedup in BinaryTree17, and to a lesser extent Fannkuch11, benchmarks is influenced by the performance of the heap allocator. Part of heap allocation involves updating statistics stored in 64 bit quantities, which flow into runtime.MemStats. During the 1.1 cycle, some quick work on the part of the Atom symbol removed many of these 64 bit operations, which shows as decreased run time in these benchmarks.
net/http
Across all the samples, net/http benchmarks have benefited from the new poller implementation as well as the pure Go improvements to the net/http package through the work of Brad Fitzpatrick and Jeff Allen.
runtime
The results of the runtime benchmarks mirror those from amd64 and 386. The general trend is towards improvement, and in some cases, a large improvement, in areas like map operations.

The improvements to the Append set of benchmarks shows the benefit of a change committed by Rob Pike which avoids a call to runtime.memmove when appending small amounts of data to a []byte.
The common theme across all the samples is the regression in some channel operations. This may be attributable to the high cost of performing atomic operations on arm platforms. Currently all atomic operations are implemented by the runtime package, but in the future they may be handled directly in the compiler which could reduce their overhead.
The CompareString benchmarks show a smaller improvement than other platforms because CL 8056043 has not yet been backported to arm.
Conclusion
With the additions of cgo support, throughput improvements in the net package, and improvements to code generation and garbage collector, Go 1.1 represents a significant milestone for writing Go programs targeting arm.
To wrap up this series of articles it is clear that Go 1.1 delivers on its promise of a general 30-40% improvement across all three supported architectures. If we consider the relative improvements across compilers, while 6g remains the flagship compiler and benefits from the fastest underlying hardware, 8g and 5g show a greater improvement relative to the Go 1.0 release of last year.
But wait, there is more
If you’ve enjoyed this series of posts and want to follow the progress of Go 1.2 I’ll soon be opening a branch of autobench which will track Go 1.1 vs tip (1.2). I’ll post and tweet the location when it is ready.
Since the Go 1.2 change window was opened on May 14th, the allocator and garbage collector have already received improvements from Dmitry Vyukov and the Atom symbol aimed at further reducing the cost of GC, and Carl Shapiro has started work on precise collection of stack allocated values.
Also for Go 1.2 are proposals for a better memory allocator, and a change to the scheduler to give it the ability to preempt long running goroutines, which is aimed at reducing GC latency.
Finally, Go 1.2 has a release timetable. So while we can’t really say what will or will not making it into 1.2, we can say that it should be done by the end of 2013.
Thank you David for your analysis!
It is a pity the performance regression for channels, in particular in the Raspberry Pi. I suppose that it was done in some other way before, other than atomic operations, and that other way cannot be used now… I’m using the RPi to program in Go (just learning, nothing serious) and it works just fine :)
You mentioned that Go1.1 includes support for the Raspberry Pi for the first time, so, how is the comparison made? with which version?
Thanks.
> It is a pity the performance regression for channels, in particular in the Raspberry Pi. I suppose that it was done in some other way before, other than atomic operations, and > that other way cannot be used now… I’m using the RPi to program in Go (just learning, nothing serious) and it works just fine :)
While the runtime microbenchmarks show a regression, these are benchmarks designed to stress a particular function for measurement. As you can see from the other benchmarks, the overall improvement is still well in the black.
> You mentioned that Go1.1 includes support for the Raspberry Pi for the first time, so, how is the comparison made? with which version?
Have a look at the patches/ subdirectory in the autobench repo, for Go 1.0, we patch in the small part from Go 1.1 that removes the problematic VPF3 instruction.
Thanks for your answer! Yes, the channel regression I’m sure is not important in a real application :) I love the compilation speed of Go, compared to C++, in a small device like the Pi.
Thank you. If you’re a RPi fan, then maybe you’d like to try these experimental Go 1.1 debs for Raspbian.
% wget http://dave.cheney.net/paste/golang-{go,src}_1.1-2_armhf.deb
% sudo dpkg -i golang-{go,src}_1.1-2_armhf.deb
Thanks for doing this series, Dave. It’s been wonderful to see where the improvements/regressions have came from, as well as the resulting stats themselves. Autobench is also neat, thanks for introducing that tool. -Mark
Pingback: Go 1.1 performance improvements | thoughts...