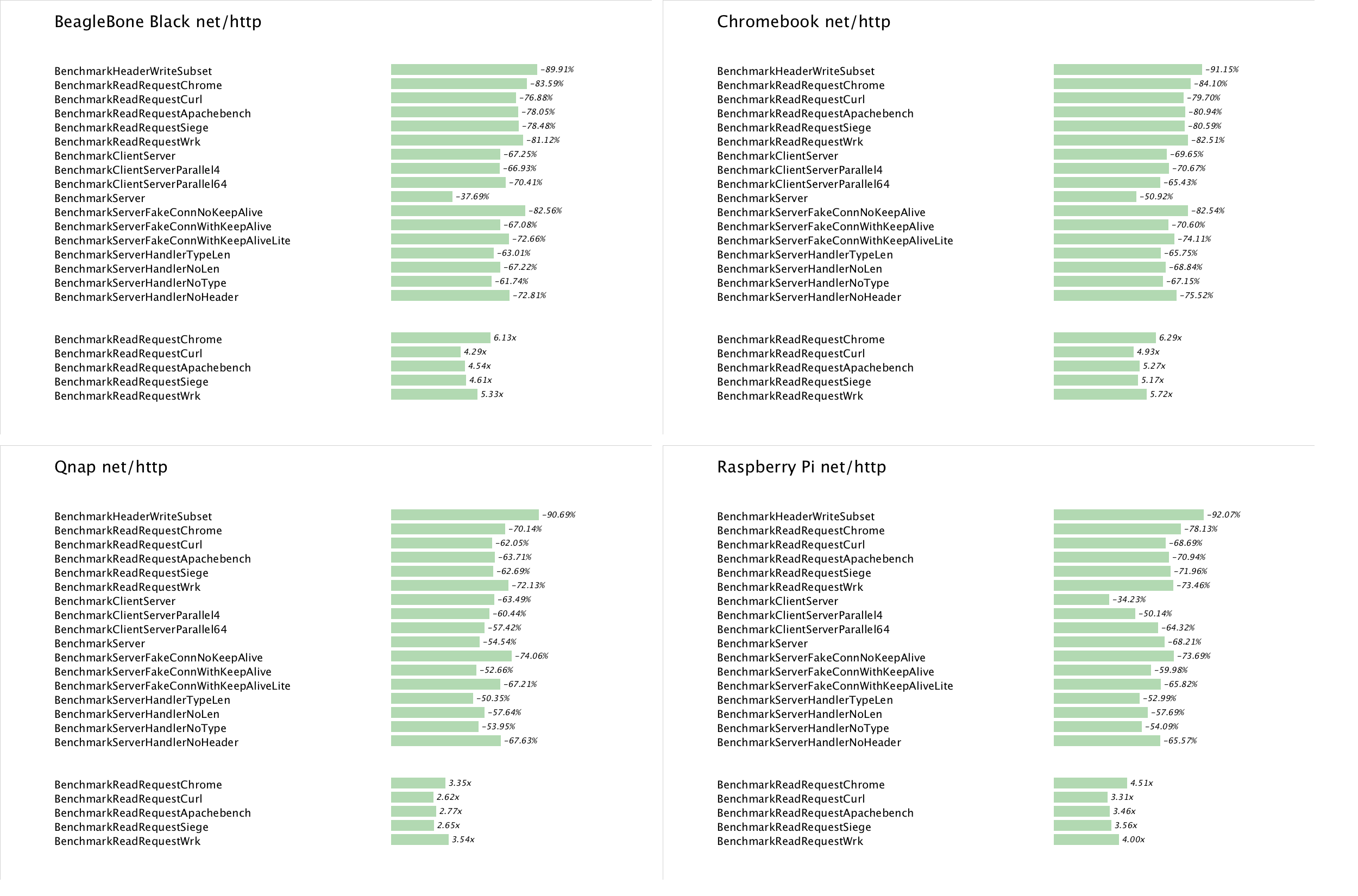
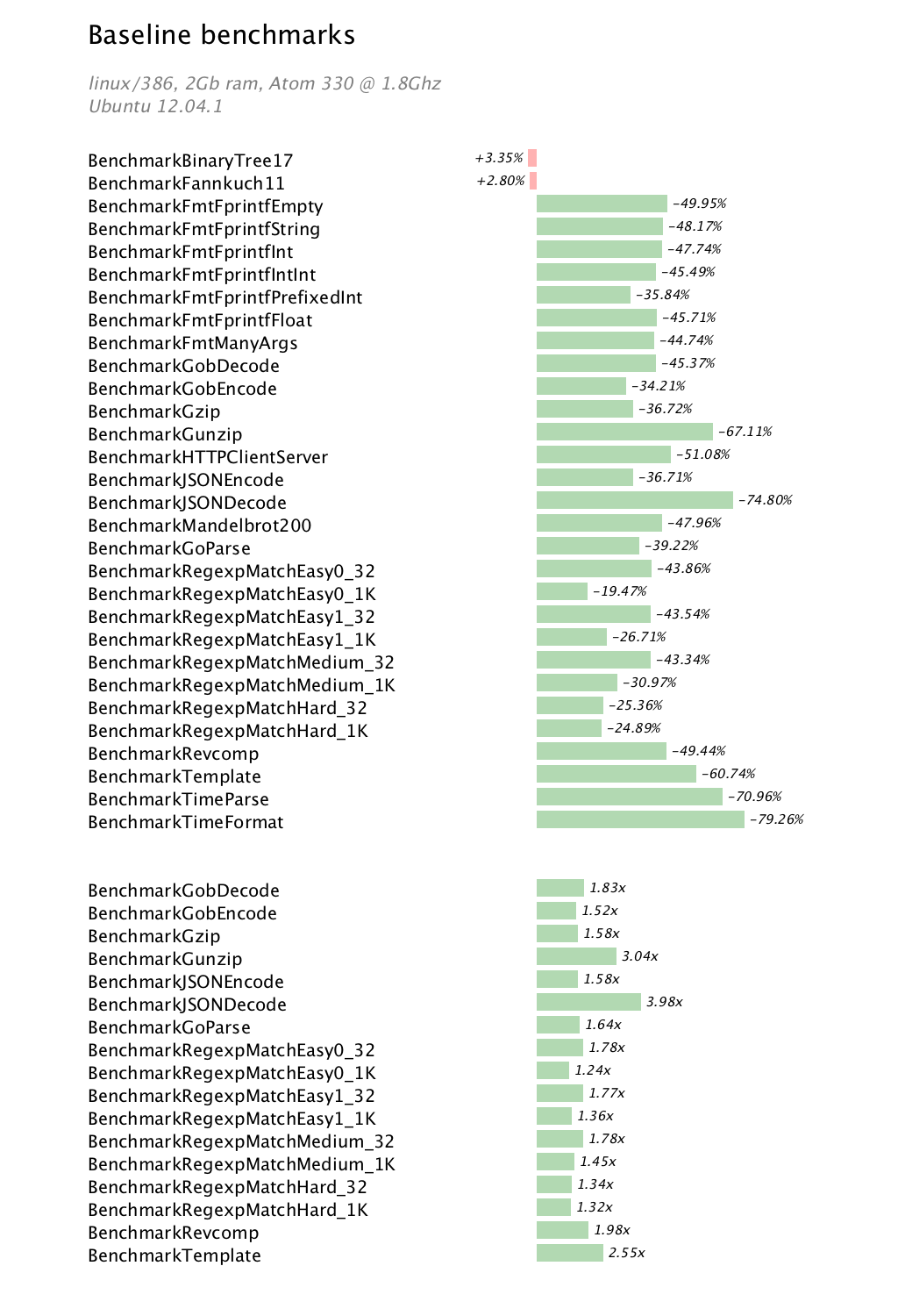
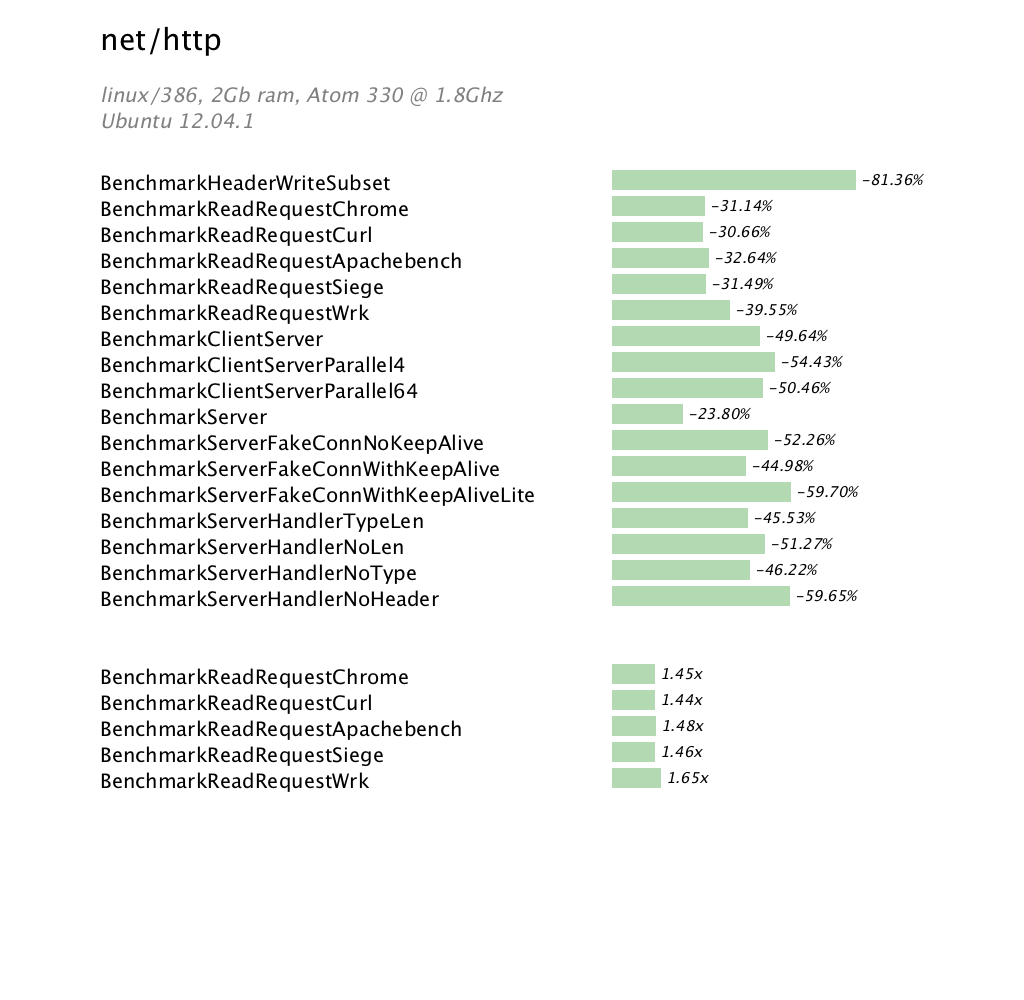
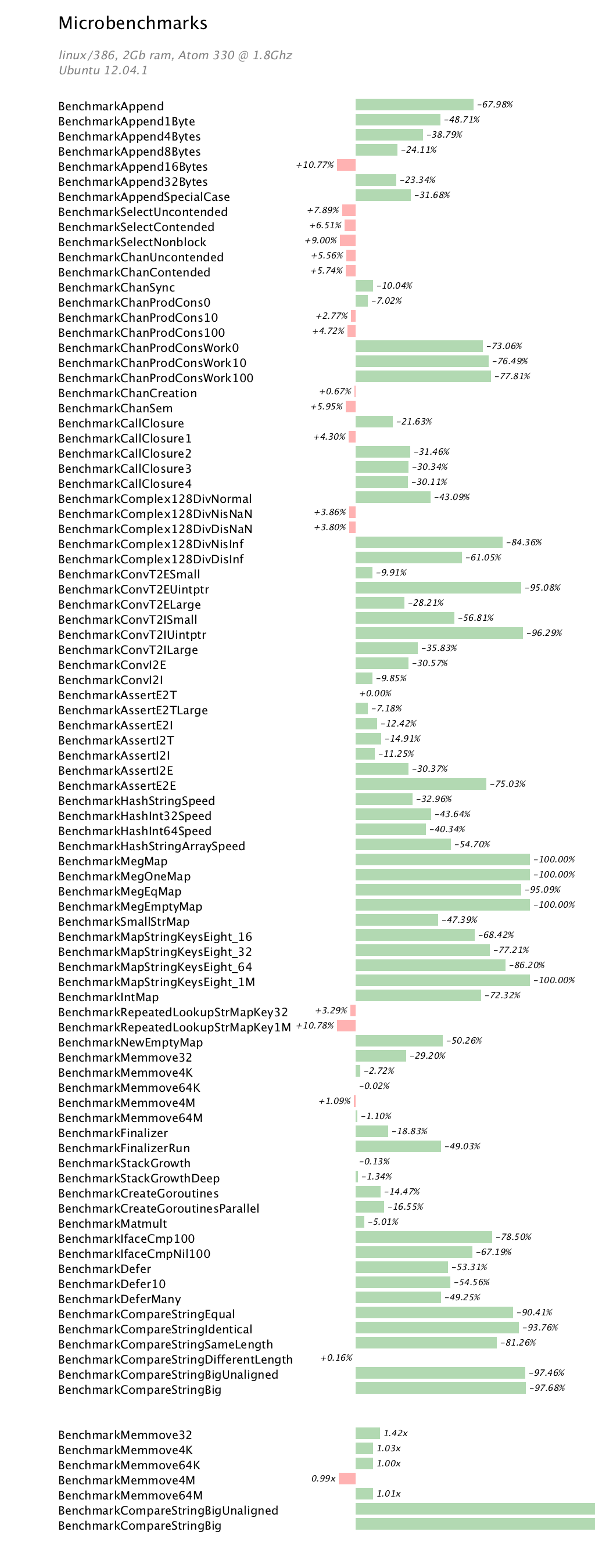
This post is based on a talk I gave to the Sydney Go users group in mid April 2013 describing the Go build process.
Frequently on mailing list or IRC channel there are requests for documentation on the details of the Go compiler, runtime and internals. Currently the canonical source of documentation about Go’s internals is the source, which I encourage everyone to read. Having said that, the Go build process has been stable since the Go 1.0 release, so documenting it here will probably remain relevant for some time.
This post walks through the nine steps of the Go build process, starting with the source and ending with a fully tested Go installation. For simplicity, all paths mentioned are relative to the root of the source checkout, $GOROOT/src.
For background you should also read Installing Go from source on the golang.org website.
Step 1. all.bash
% cd $GOROOT/src
% ./all.bash
The first step is a bit anticlimactic as all.bash just calls two other shell scripts; make.bash and run.bash. If you’re using Windows or Plan 9 the process is the same, but the scripts end in .bat or .rc respectively. For the rest of this post, please substitute the extension appropriate for your operating system.
Step 2. make.bash
. ./make.bash --no-banner
make.bash is sourced from all.bash so that calls to exit will terminate the build process properly. make.bash has three main jobs, the first job is to validate the environment Go is being compiled in is sane. The sanity checks have been built up over the last few years and generally try to avoid building with known broken tools, or in environments where the build will fail.
Step 3. cmd/dist
gcc -O2 -Wall -Werror -ggdb -o cmd/dist/dist -Icmd/dist cmd/dist/*.c
Once the sanity checks are complete, make.bash compiles cmd/dist. cmd/dist replaces the Makefile based system which existed before Go 1 and manages the small amounts of code generation in pkg/runtime. cmd/dist is a C program which allows it to leverage the system C compiler and headers to handle most of the host platform detection issues. cmd/dist always detects your host’s operating system and architecture, $GOHOSTOS and $GOHOSTARCH. These may differ from any value of $GOOS and $GOARCH you may have set if you are cross compiling. In fact, the Go build process is always building a cross compiler, but in most cases the host and target platform are the same. Next, make.bash invokes cmd/dist with the bootstrap argument which compiles the supporting libraries, lib9, libbio and libmach, used by the compiler suite, then the compilers themselves. These tools are also written in C and are compiled by the system C compiler.
echo "# Building compilers and Go bootstrap tool for host, $GOHOSTOS/$GOHOSTARCH."
buildall="-a"
if [ "$1" = "--no-clean" ]; then
buildall=""
fi
./cmd/dist/dist bootstrap $buildall -v # builds go_bootstrap
Using the compiler suite, cmd/dist then compiles a version of the go tool, go_bootstrap. The go_bootstrap tool is not the full go tool, for example pkg/net is stubbed out which avoids a dependency on cgo. The list of directories containing packages or libraries be compiled, and their dependencies is encoded in the cmd/dist tool itself, so great care is taken to avoid introducing new build dependencies for cmd/go.
Step 4. go_bootstrap
Now that go_bootstrap is built, the final stage of make.bash is to use go_bootstrap to compile the complete Go standard library, including a replacement version of the full go tool.
echo "# Building packages and commands for $GOOS/$GOARCH."
"$GOTOOLDIR"/go_bootstrap install -gcflags "$GO_GCFLAGS" \
-ldflags "$GO_LDFLAGS" -v std
Step 5. run.bash
Now that make.bash is complete, execution falls back to all.bash, which invokes run.bash. run.bash‘s job is to compile and test the standard library, the runtime, and the language test suite.
bash run.bash --no-rebuild
The --no-rebuild flag is used because make.bash and run.bash can both invoke go install -a std, so to avoid duplicating the previous effort, --no-rebuild skips the second go install.
# allow all.bash to avoid double-build of everything
rebuild=true
if [ "$1" = "--no-rebuild" ]; then
shift
else
echo '# Building packages and commands.'
time go install -a -v std
echo
fi
Step 6. go test -a std
echo '# Testing packages.'
time go test std -short -timeout=$(expr 120 \* $timeout_scale)s
echo
Next run.bash is to run the unit tests for all the packages in the standard library, which are written using the testing package. Because code in $GOPATH and $GOROOT live in the same namespace, we cannot use go test ... as this would also test every package in $GOPATH, so an alias, std, was created to address the packages in the standard library. Because some tests take a long time, or consume a lot of memory, some tests filter themselves with the -short flag.
Step 7. runtime and cgo tests
The next section of run.bash runs a set of tests for platforms that support cgo, runs a few benchmarks, and compiles miscellaneous programs that ship with the Go distribution. Over time this list of miscellaneous programs has grown as it was found that when they were not included in the build process, they would inevitably break silently.
Step 8. go run test
(xcd ../test
unset GOMAXPROCS
time go run run.go
) || exit $?
The penultimate stage of run.bash invokes the compiler and runtime tests in the test folder directly under $GOROOT. These are tests of the low level details of the compiler and runtime itself. While the tests exercise the specification of the language, the test/bugs and test/fixedbugs sub directories capture unique tests for issues which have been found and fixed. The test driver for all these tests is $GOROOT/test/run.go which is a small Go program that runs each .go file inside the test directory. Some .go files contain directives on the first line which instruct run.go to expect, for example, the program to fail, or to emit a certain output sequence.
Step 9. go tool api
echo '# Checking API compatibility.'
go tool api -c $GOROOT/api/go1.txt,$GOROOT/api/go1.1.txt \
-next $GOROOT/api/next.txt -except $GOROOT/api/except.txt
The final step of run.bash is to invoke the api tool. The api tool’s job is to enforce the Go 1 contract; the exported symbols, constants, functions, variables, types and methods that made up the Go 1 API when it shipped in 2012. For Go 1 they are spelled out in api/go1.txt, and Go 1.1, api/go1.1.txt. An additional file, api/next.txt identifies the symbols that make up the additions to the standard library and runtime since Go 1.1. Once Go 1.2 ships, this file will become the contract for Go 1.2, and there will be a new next.txt. There is also a small file, except.txt, which contains exceptions to the Go 1 contract which have been approved. Additions to the file are not expected to be taken lightly.
Additional tips and tricks
You’ve probably figured out that make.bash is useful for building Go without running the tests, and likewise, run.bash is useful for building and testing the Go runtime. This distinction is also useful as the former can be used when cross compiling Go, and the latter is useful if you are working on the standard library.
Update: Thanks to Russ Cox and Andrew Gerrand for their feedback and suggestions.