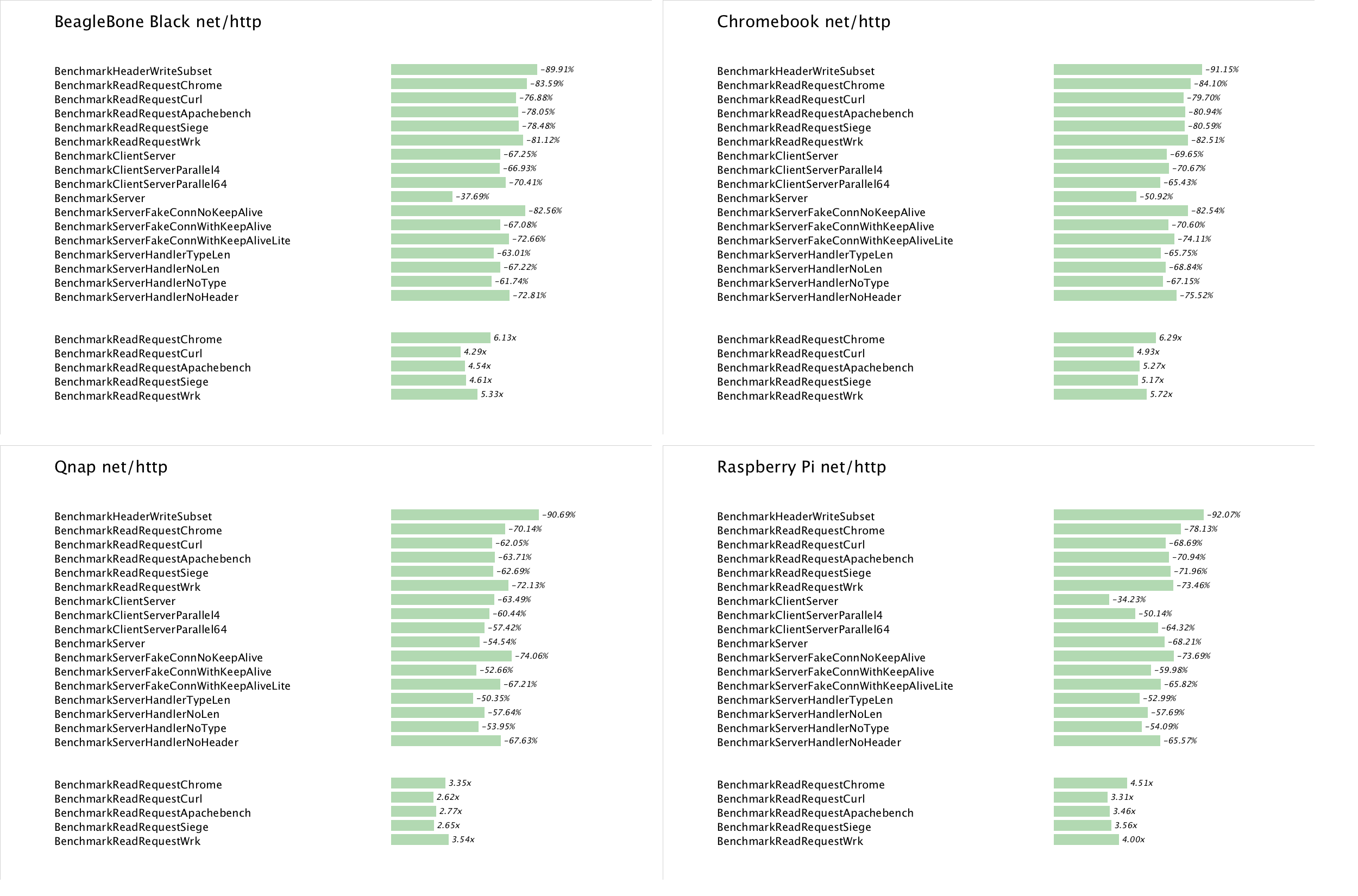
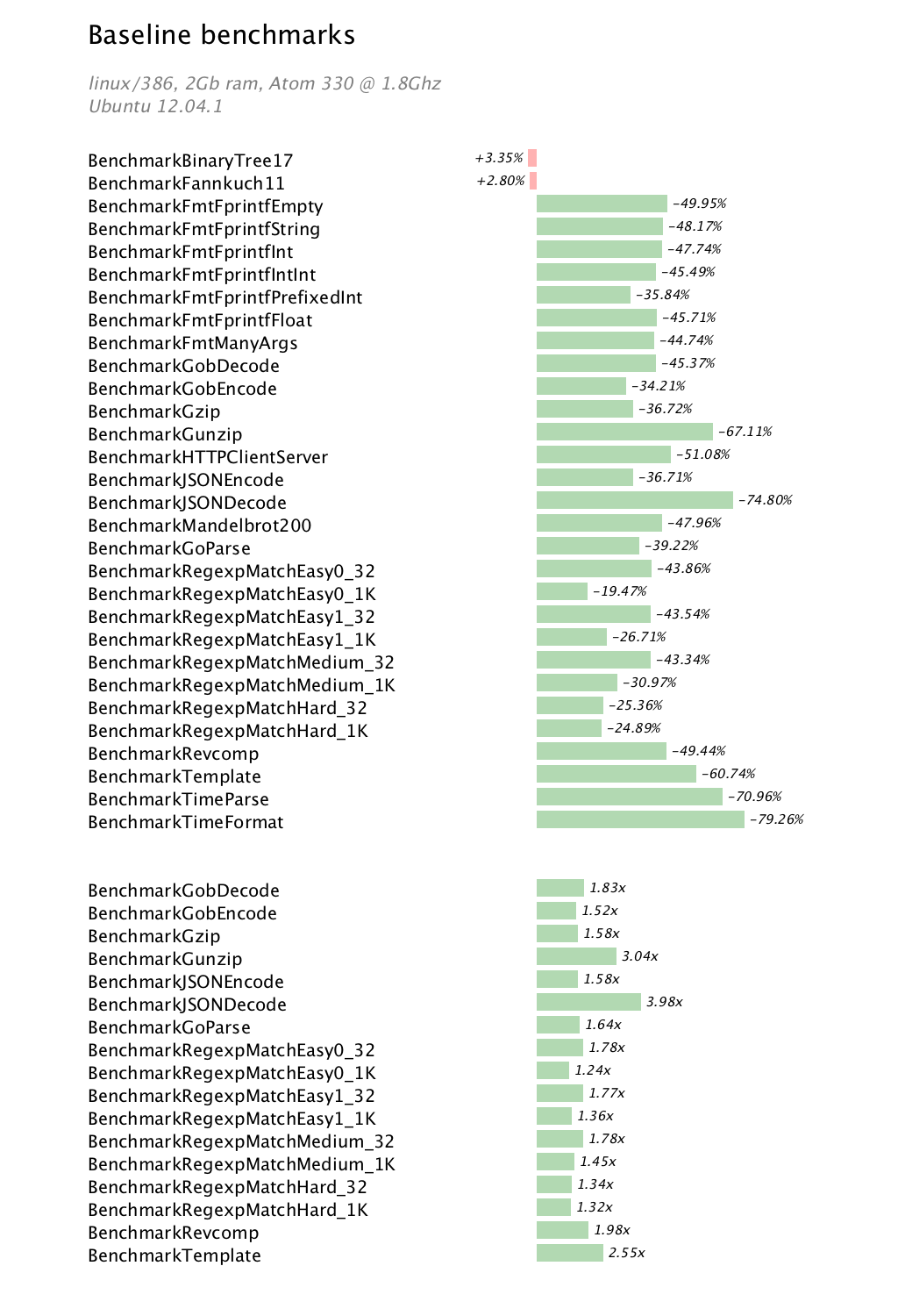
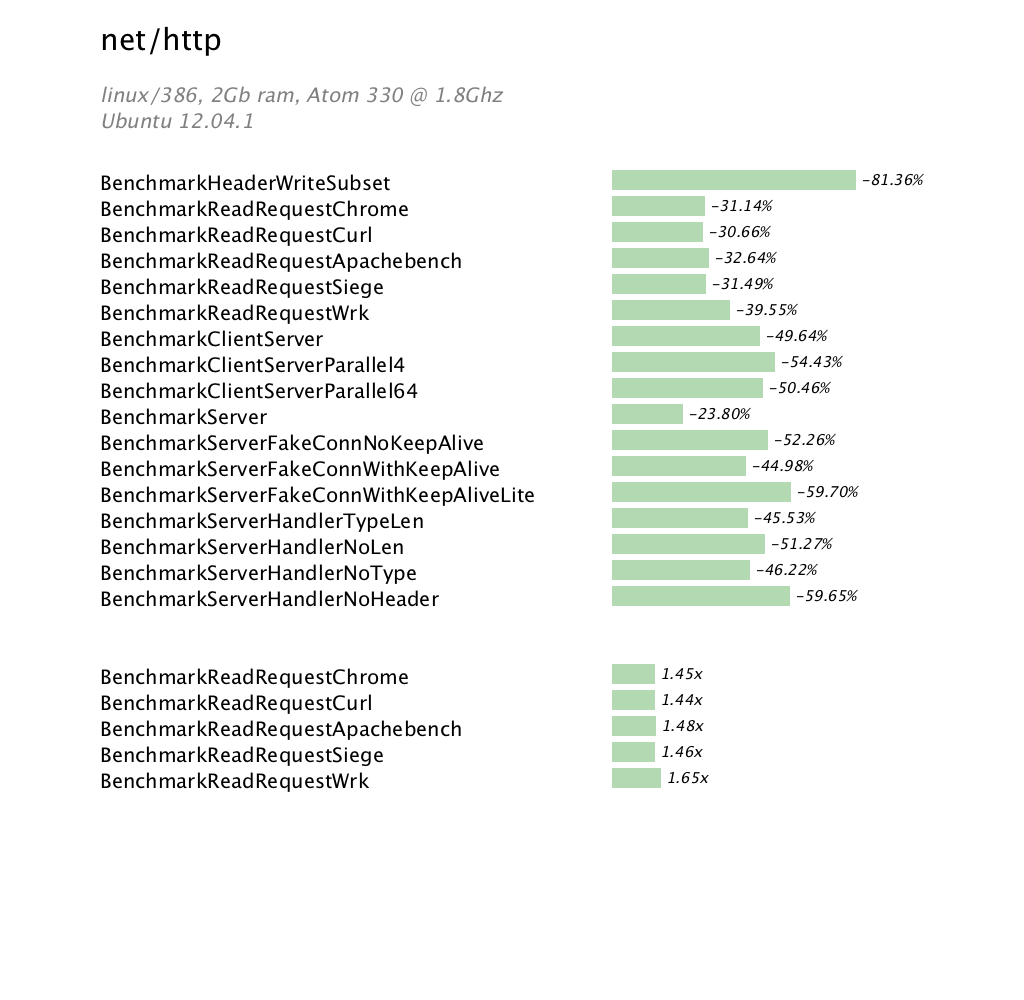
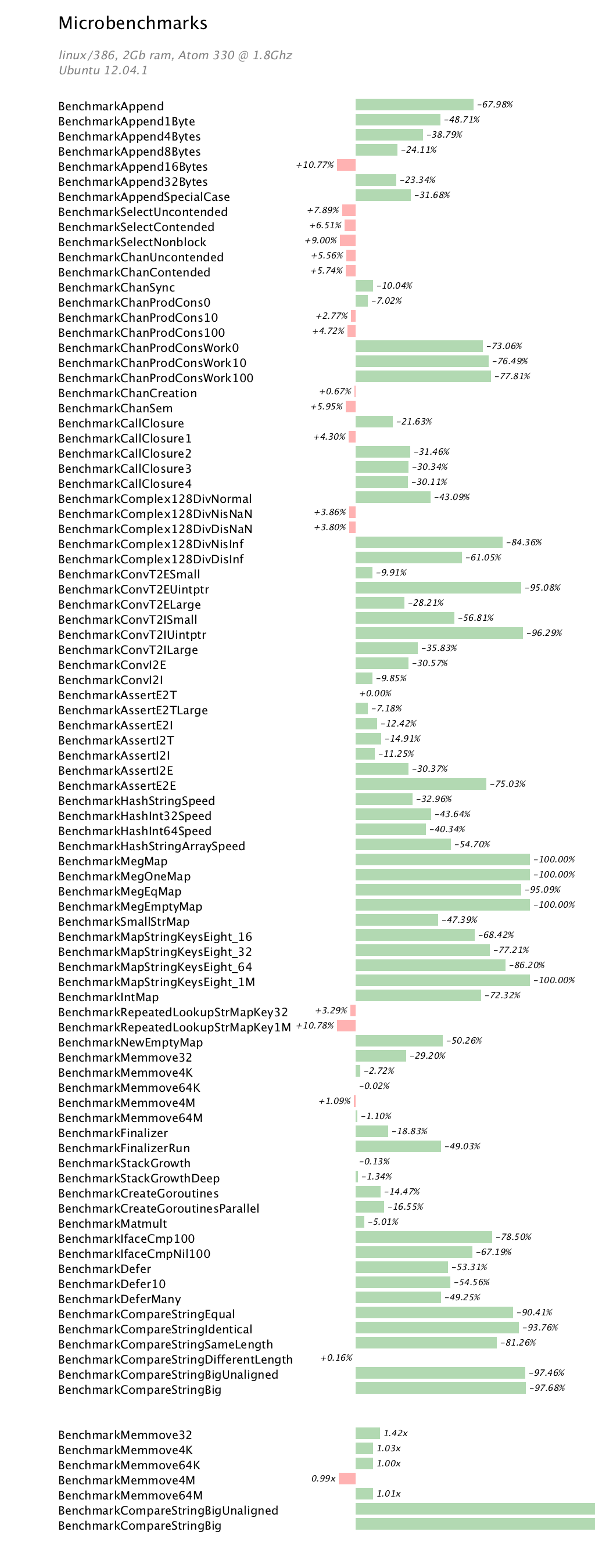
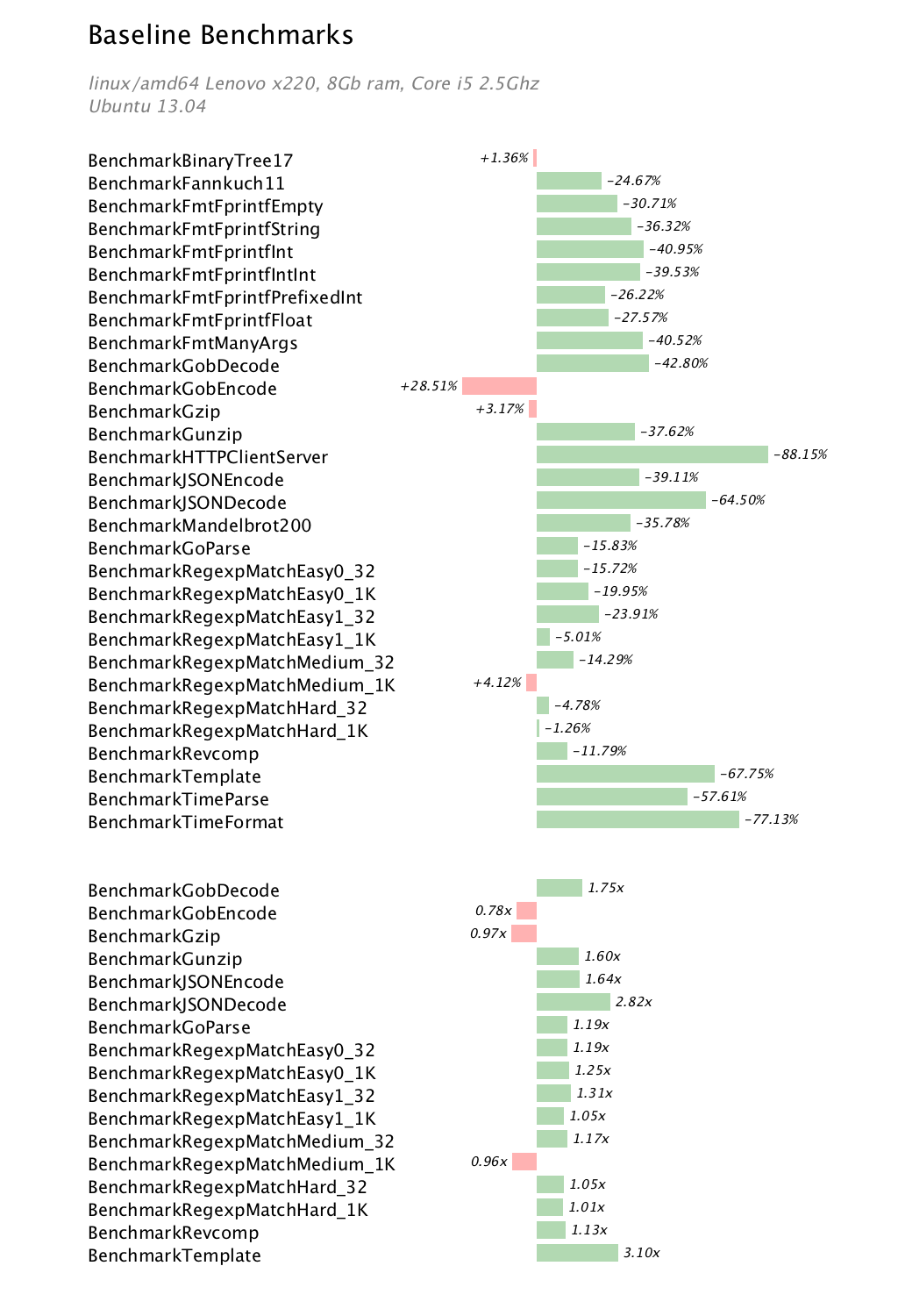
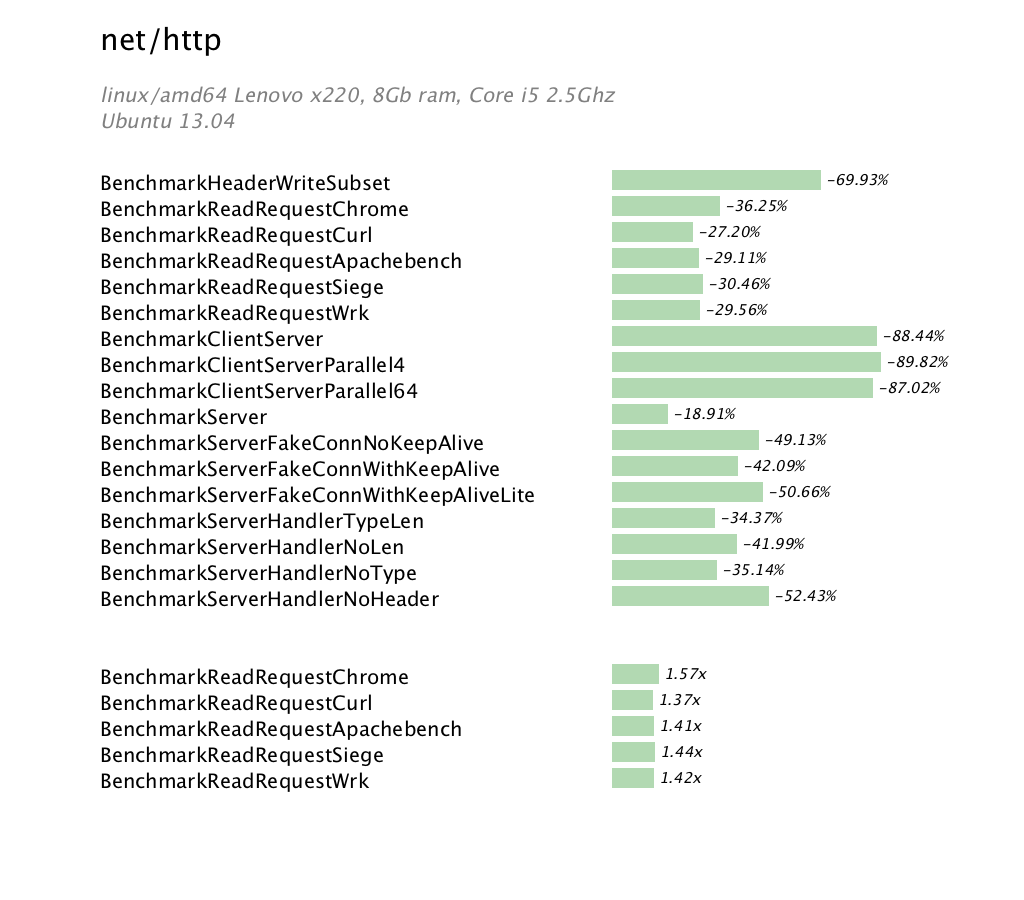
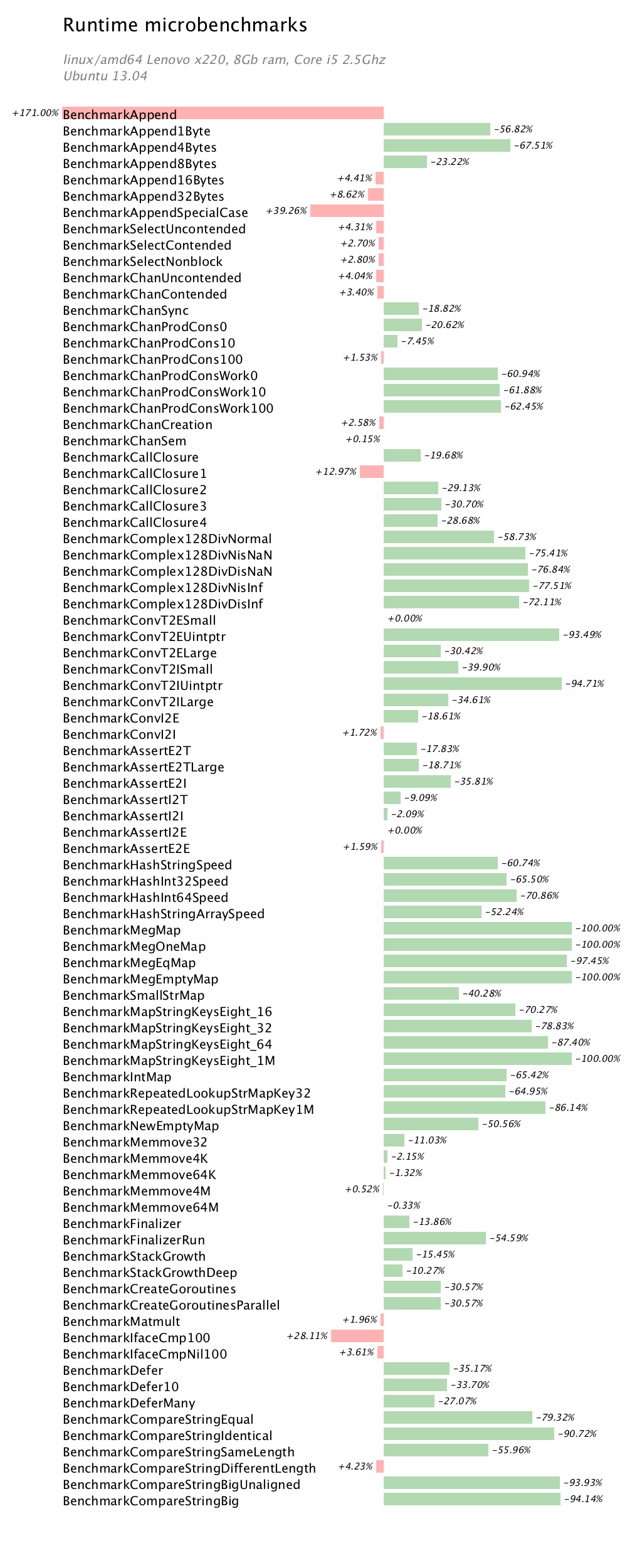
Introduction
This is a short post to explain why it is not necessary to set $GOROOT when compiling or using Go.
TL;DR
In general1 it is not necessary to set the $GOROOT environment variable when compiling or using Go 1.0 or later. In fact, setting $GOROOT can lead to hard to debug problems if you have multiple versions of Go present on your computer.
You still need to set $GOPATH. Since Go 1.0 setting $GOPATH has been highly recommended, and with the release of Go 1.1, it is considered mandatory.
Why isn’t GOROOT required anymore ?
You’re still reading ? Excellent. Now for some history.
The history of the GO* environment variables
Go old timers may remember when not only $GOROOT, but $GOOS and $GOARCH were required environment variables. These were required because the Makefile based build system used lots of includes which used $GOROOT as their base path.
By the time the go tool was introduced, prior to Go 1.0, $GOOS and $GOARCH were optional as the build scripts were able to detect the host’s operating system and cpu architecture. With the release of Go 1.0, and the introduction of the cmd/dist bootstrap build tool, $GOOS and $GOARCH became truly optional. They are now only used when cross compiling.
Go 1.0 also introduced $GOPATH based workspaces. If you’ve read this far, you probably know what a $GOPATH workspace is. But in case you don’t, this is documented on the golang.org website, and in this screencast.
Okay, so I don’t need $GOOS or $GOARCH, but what about $GOROOT ?
$GOROOT has always been defined as a pointer to the root of your Go installation. In the old Makefile based build system, it was used as the base path for including other Makefiles, and since Go 1.0 it is used by the go tool to find the compiler (stored in $GOROOT/pkg/tool/$GOOS_$GOARCH) and the standard library (also in $GOROOT/pkg/$GOOS_$GOARCH). If you are a Java user, $GOROOT is similar in effect to $JAVA_HOME.
When you compile Go from source, the value of $GOROOT is automatically discovered2 (it is one directory up from the all.bash script) and then embedded into the go tool built from that source tree. You can see this when you run go env
% echo $GOROOT % go env GOROOT /home/dfc/go
The binary distributions you download from the golang.org website, or install from your operating system distribution also have the correct $GOROOT value embedded into the go tool binary. Here is an example from a Ubuntu 12.04 system which ships with Go 1.0.
% dpkg -l golang-{go,src} | grep ^ii
ii golang-go 2:1-5 Go programming language compiler
ii golang-src 2:1-5 Go programming language compiler - source files
% which go
/usr/bin/go
% go env GOROOT
/usr/lib/go
You can see that the go tool is installed in /usr/bin/go and $GOROOT is embedded as /usr/lib/go.
So, why shouldn’t I set $GOROOT anymore ?
You should not set $GOROOT because the correct value is already embedded in the go tool.
Setting $GOROOT will override the value stored in the go tool which could lead to the go tool from one version of Go pointing to the compiler and standard library from another version.
There are only two cases that where you may have to set a $GOROOT environment. These are both described in the installation page on the golang.org website. For completeness I will recap them here
- You are a Linux, FreeBSD or OS X user using the the zip or tarball binary downloads from the golang.org website. These binaries have a
$GOROOTvalue of/usr/local/goand recommend you unpack them into that location. If you choose not to do this, then you must set$GOROOTto the location you chose. - You are a Windows user using the zip binary download from the golang.org website. These binaries have a
$GOROOTvalue ofC:\Go. If you place Go somewhere else on your system then you must set$GOROOTto the location you chose.
Super nerdy bonus detail
This post has explained how $GOROOT is automatically discovered when compiling from source. I’ve also shown that the build scripts can detect when that value doesn’t match the path that all.bash is invoked from. So, how do operating system distributions set $GOROOT when they normally compile Go in a temporary build directory or chroot? The answer is the $GOROOT_FINAL value, which is used to override the $GOROOT location stored in the go tool.
For example, the Debian/Ubuntu build process will supply a value for $GOROOT_FINAL of /usr/lib/go. This frees it to leave $GOROOT unset, making the build process happy. After the build, the build process will install the go tool in /usr/bin, and the compilers, sources and packages in /usr/lib/go.
- There are a few cases where it is required if using the binary distributions of Go, which are described in this post.
- That is, if you haven’t set
$GOROOT. Although the build system will detect when the parent directory ofall.bashdoes not match$GOROOT.