The question of how to set up a new Go project appears commonly on the golang-nuts mailing list.
Normally the advice for how to structure Go code centres around “read the standard library”, but the standard library is not a great deal of use to newcomers in the respect as:
- You don’t
go getpackages from the standard library, they’re always present as part of your Go installation - The standard library doesn’t live in your
$GOPATHso its layout is less useful as an example.
This article attempts to illustrate common patterns for structuring Go projects using real life packages as examples.
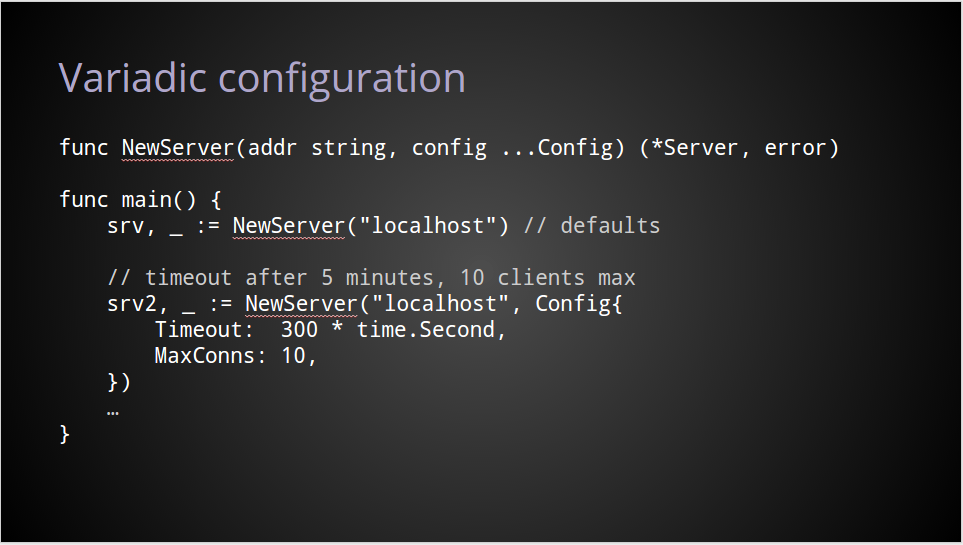
Creating a package
A package is a directory inside your $GOPATH/src directory containing, amongst other things, .go source files.
The name of the package should match the name of the directory in which its source is located. If you package is called logger, then its source files may be located in
$GOPATH/src/github.com/yourname/logger
Package names should be all lower case. Sorry, it’s 2014, and there are still operating systems that can’t cope with mixed case.
Package names, and thus the package’s directory, should contain only letters, numbers if you must, but absolutely no punctuation.
The name of a package is part of the name of every type, constant, variable, or function, exported by that package. It may look odd when inside the package, but always consider what it looks like the caller.
Avoid repetition. bytes.Buffer not bytes.BytesBuffer, strings.Reader not strings.StringReader, etc.
For more advice on naming, see Andrew Gerrand’s excellent talk on Go naming.
All the files in a package’s directory must have the same package declaration, with one exception.
For testing, your test files, those ending with _test.go, may declare themselves to be in the same package, but with _test appended to the package declaration. This is known as an external test. For now, just accept that you can’t put the code for multiple packages into one directory.
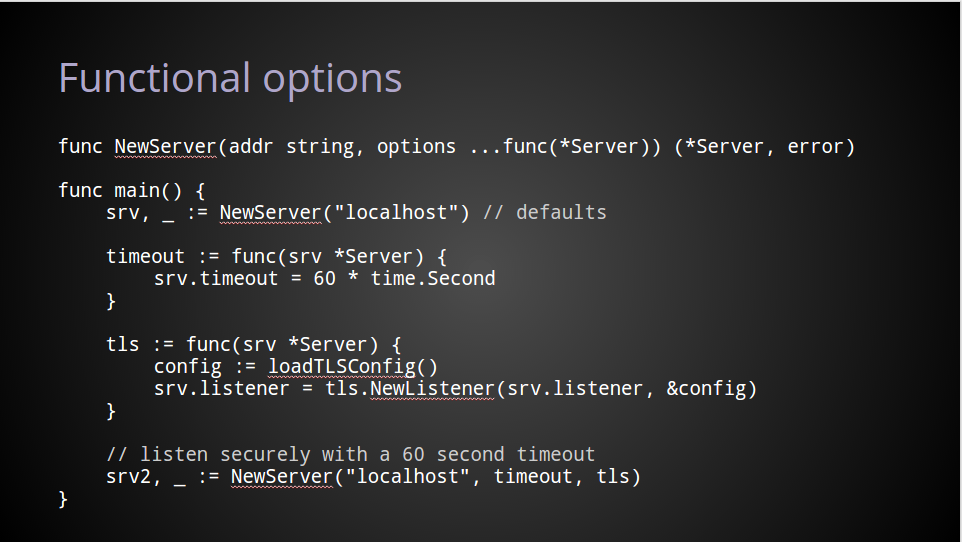
Main packages
Some packages are actually commands, these carry the declaration package main.
Main packages deviate from the previous statement about the package declaration and the packages’ directory being the same. In the case of commands, the name of the command is taken from the name of the package’s directory.
This obviates the need to use flags like -o when building or installing Go programs — the name of the command is automatically inferred from the name of the directory containing the program.
Everything in Go works with packages.
The go commands; go build, go install, go test, go get, all work with packages, not individual files.
go run is the exception to this rule. It is intended only to be a local version of the go playground. Avoid using it for anything more trivial than a program you would otherwise run in the playground.
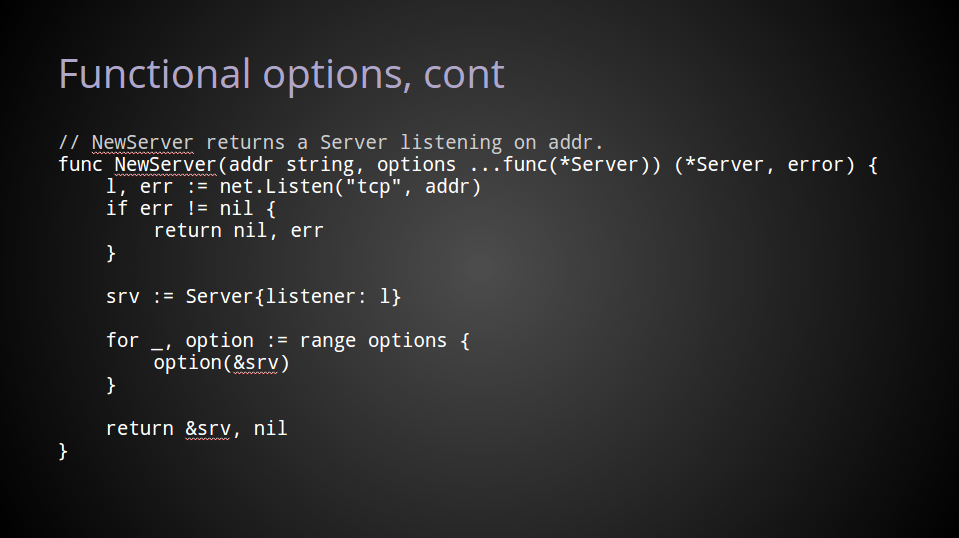
The import path
All packages exist inside a directory tree rooted at $GOPATH/src. Because of this, a package’s import path and a package’s name are often different.
Don’t confuse this with the previous statement that a package’s name, its package declaration, should match the directory in which the package’s files live.
The import path is effectively the full path to your package. It is what differentiates your logger package from the dozens of others that are also named logger.
Note: There is no concept of sub packages in Go. This is why the ioutil package is called ioutil, not util with an import path of io/util. This avoids local namespace collisions.
VCS names in import paths
In other languages it is quite common to ensure your package has a unique namespace by prefixing it with your company name, say com.sun.misc.Unsafe. If everyone only writes packages corresponding to domains that they control, then there is little possibility of a collision.
In Go, the convention is to include the location of the source code in the package’s import path, ie
$GOPATH/src/github.com/golang/glog
However there are several important points to remember:
- This is not required by the language, it is just a feature of
go get.
go getrecognises paths that start with known code hosting sites, Github, Bitbucket, Google code, and knows how to convert the import path of the package (not the name) into the correct command to check out the code. - By following this convention you can point
go getat some source code you have in your$GOPATHand it will recursively fetch any required packages. You can even have it fetch all the source code by callinggo get import/path.
This has turned out to be a very simple way of distributing Go programs. - This does not mean that you need to be online to use the Go compiler, or that you need to have made your project public. Remember, the naming of packages is only an aide to
go get, andgo getis an optional command.
Sample repositories
With this background in place, I’m going to walk through some examples of the various types, or styles, of Go projects. Hopefully by studying them you will understand how to structure your projects in a way that interoperates well with others.
A single package
The simplest example of a Go project is a repository that contains only one package. The example I have chosen is Keith Rarick’s fs package, https://github.com/kr/fs.
This is the simplest Go project, a single package with the code at the root of the repository. The import path for this project would be
import "github.com/kr/fs"
Multiple packages
The next logical step after creating a repository containing a single package is a more complicated project with multiple packages in a single repository.
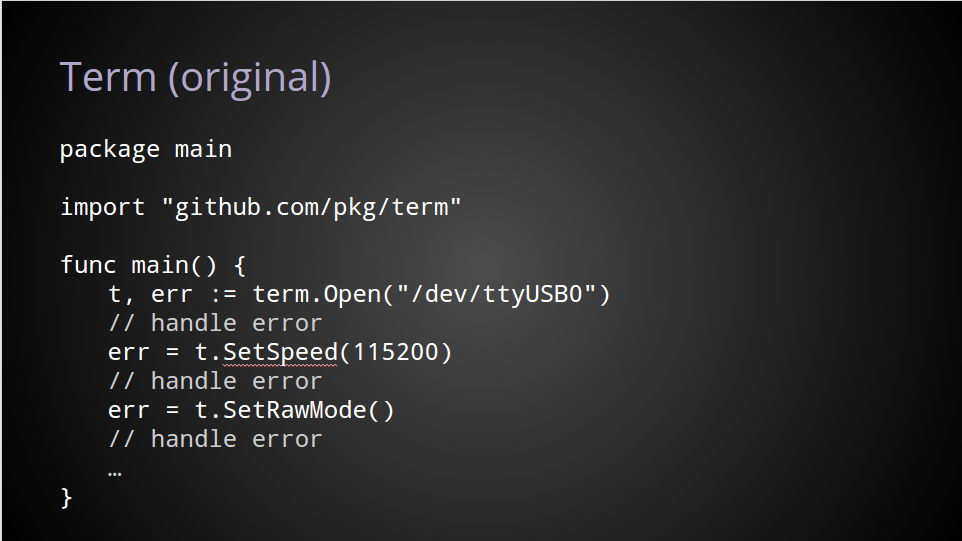
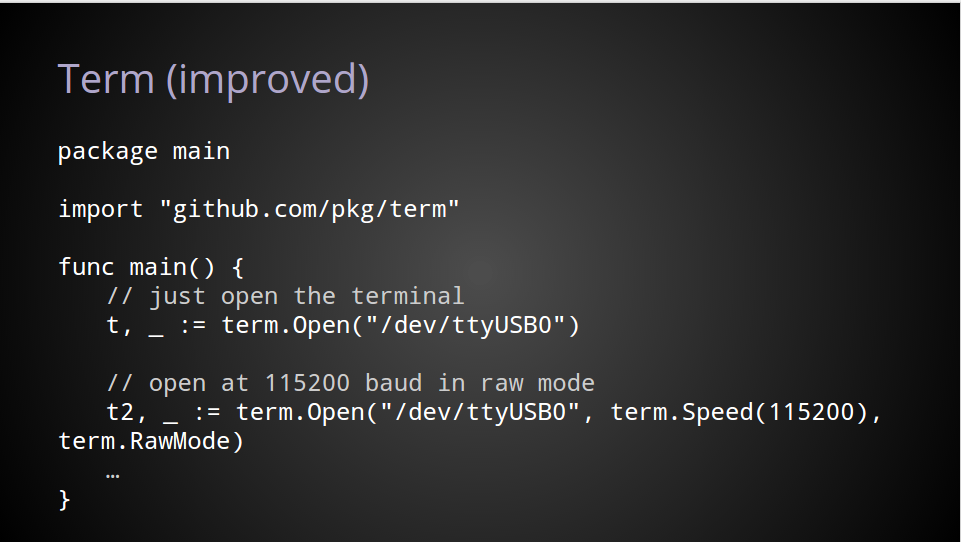
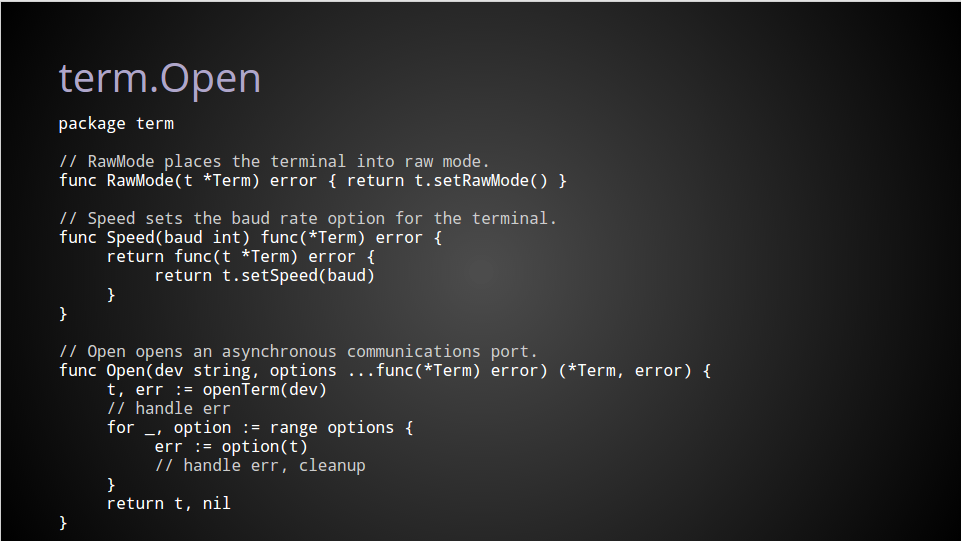
I’ve chosen my own term project, https://github.com/pkg/term, which contains two packges, github.com/pkg/term, and github.com/pkg/term/termios, containing syscalls to handle the various termios(3) syscalls.
Even though Go does not have a notion of sub packages, term and term/termios live in the same repository. I could have created two projects, https://github.com/pkg/term and https://github.com/pkg/termios, but as they are closely related, it made sense to place the source for both packages in the same Github repository.
To use this project, you would import it with
import "github.com/pkg/term"
A command
godep, https://github.com/tools/godep, is an example of a repository containing one command package at its root.
Because the source for this package declares it to be in package main when compiled the program will appear as $GOPATH/bin/godep.
% go get -v github.com/tools/godep github.com/tools/godep (download) github.com/kr/fs golang.org/x/tools/go/vcs github.com/tools/godep
A command and a package
The fourth example shows how to structure a Go project that includes shared logic in a package, and a command which uses that logic. The project I have chosen is the platinum searcher by Monochromegane, https://github.com/monochromegane/the_platinum_searcher, an excellent replacement for ack or ag written in pure Go.
At the root of the project is the the_platinum_searcher package (this does break the prohibition on punctuation in package names) containing the logic. In the cmd/pt subdirectory is the main package. Using the globbing feature of go get installing pt is simply
% go get -u github.com/monochromegane/the_platinum_searcher/...
This is not the only way to lay out this style of package. Other examples may place the command, package main, at the root of the repository and the packages containing the logic of the project in a subdirectory. An example of this is Steve Francia’s Hugo, https://github.com/spf13/hugo.
In both examples the intention is to keep as much logic out of the command, as commands cannot be imported by other packages, limiting the reuse of code inside main packages.
Multiple commands and multiple packages
The final example, the go.tools subrepo, https://code.google.com/p/go/source/browse/?repo=tools, combines all of the above.
The tools repo contains many Go packages, and a burgeoning cmd subdirectory of Go programs. As a resource of well written, contemporary, Go code, you could do far worse.
Further reading
- How to write Go code, from the golang.org website.
- Organising Go code by David Crawshaw, presented at Google I/O 2014.
- Contributing to Open Source Git Repositories in Go by Katrina Owen.