This is a progress report on the Go toolchain improvements during the 1.8 development cycle.
Now we’re well into November, the 1.8 development window is closing fast on the few remaining in fly change lists, with the remainder being told to wait until the 1.9 development season opens when Go 1.8 ships in February 2017.
For more in this series, read my previous post on the Go 1.8 toolchain improvements from September, and my post on the improvements to the Go toolchain in the 1.7 development cycle.
Faster compilation
Since Go 1.5, released in August 2015, compile times have been significantly slower than Go 1.4. Work on addressing this slow down started in ernest in the Go 1.7 cycle, and is still ongoing.
Robert Griesemer and Matthew Dempsky’s worked on rewriting the parser to make it faster and remove many of the package level variables inherited from the previous yacc based parser. This parser produces a new abstract syntax tree while the rest of the compiler expects the previous yacc syntax tree. For 1.8 the new parser must transform its output into the previous syntax tree for consumption by the rest of the compiler. Even with this extra transformation step the new parser is no slower than the previous version and plans are being made to remove this transformation requirement in Go 1.9.
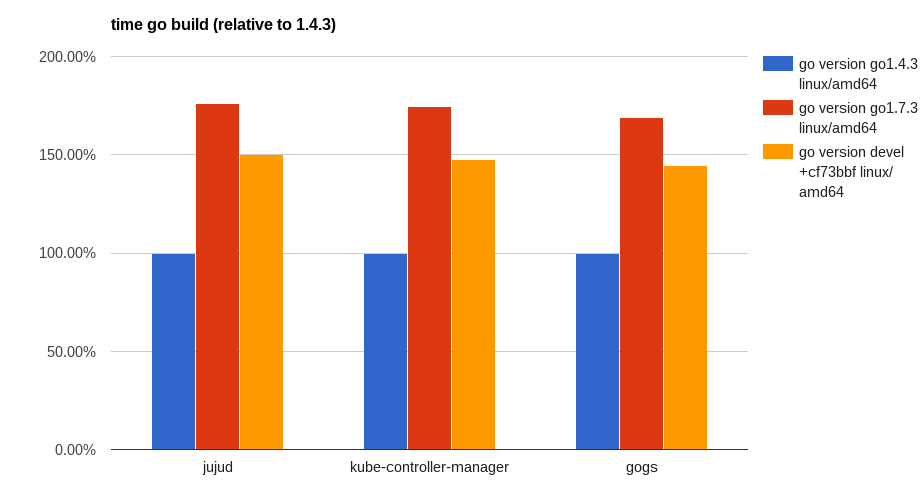
Compile time for full build relative to Go 1.4.3
The take away is Go 1.8 is on target to improve compile times by an average of 15% over Go 1.7. Compared to the 3-5% improvements reported two months prior, it’s nice to know that there is still blood in this stone.
Note: The benchmark scripts for jujud, kube-controller-manager, and gogs are online. Please try them yourself and report your findings.
Code generation improvements
The big feature of the previous 1.7 cycle was the new SSA backend for 64 bit Intel. In Go 1.8 the SSA backend has been rolled out to all the other architectures that Go supports and the old backend code has been deleted.
amd64, by virtue of being the most popular production architecture, has always been the fastest. As I reported a few months ago, the results comparing Go 1.8 to Go 1.7 on Intel architectures show middling improvement driven equally by improvements to code generation, escape analysis improvements, and optimisations to the std library.
name old time/op new time/op delta BinaryTree17-4 3.04s ± 1% 3.03s ± 0% ~ (p=0.222 n=5+5) Fannkuch11-4 3.27s ± 0% 3.39s ± 1% +3.74% (p=0.008 n=5+5) FmtFprintfEmpty-4 60.0ns ± 3% 58.3ns ± 1% -2.70% (p=0.008 n=5+5) FmtFprintfString-4 177ns ± 2% 164ns ± 2% -7.47% (p=0.008 n=5+5) FmtFprintfInt-4 169ns ± 2% 157ns ± 1% -7.22% (p=0.008 n=5+5) FmtFprintfIntInt-4 264ns ± 1% 243ns ± 1% -8.10% (p=0.008 n=5+5) FmtFprintfPrefixedInt-4 254ns ± 2% 244ns ± 1% -4.02% (p=0.008 n=5+5) FmtFprintfFloat-4 357ns ± 1% 348ns ± 2% -2.35% (p=0.032 n=5+5) FmtManyArgs-4 1.10µs ± 1% 0.97µs ± 1% -11.03% (p=0.008 n=5+5) GobDecode-4 9.85ms ± 1% 9.31ms ± 1% -5.51% (p=0.008 n=5+5) GobEncode-4 8.75ms ± 1% 8.17ms ± 1% -6.67% (p=0.008 n=5+5) Gzip-4 282ms ± 0% 289ms ± 1% +2.32% (p=0.008 n=5+5) Gunzip-4 50.9ms ± 1% 51.7ms ± 0% +1.67% (p=0.008 n=5+5) HTTPClientServer-4 195µs ± 1% 196µs ± 1% ~ (p=0.095 n=5+5) JSONEncode-4 21.6ms ± 6% 19.8ms ± 3% -8.37% (p=0.008 n=5+5) JSONDecode-4 70.2ms ± 3% 71.0ms ± 1% ~ (p=0.310 n=5+5) Mandelbrot200-4 5.20ms ± 0% 4.73ms ± 1% -9.05% (p=0.008 n=5+5) GoParse-4 4.38ms ± 3% 4.28ms ± 2% ~ (p=0.056 n=5+5) RegexpMatchEasy0_32-4 96.7ns ± 2% 98.1ns ± 0% ~ (p=0.127 n=5+5) RegexpMatchEasy0_1K-4 311ns ± 1% 313ns ± 0% ~ (p=0.214 n=5+5) RegexpMatchEasy1_32-4 97.9ns ± 2% 89.8ns ± 2% -8.33% (p=0.008 n=5+5) RegexpMatchEasy1_1K-4 519ns ± 0% 510ns ± 2% -1.70% (p=0.040 n=5+5) RegexpMatchMedium_32-4 158ns ± 2% 146ns ± 0% -7.71% (p=0.016 n=5+4) RegexpMatchMedium_1K-4 46.3µs ± 1% 47.8µs ± 2% +3.12% (p=0.008 n=5+5) RegexpMatchHard_32-4 2.53µs ± 3% 2.46µs ± 0% -2.91% (p=0.008 n=5+5) RegexpMatchHard_1K-4 76.1µs ± 0% 74.5µs ± 2% -2.12% (p=0.008 n=5+5) Revcomp-4 563ms ± 2% 531ms ± 1% -5.78% (p=0.008 n=5+5) Template-4 86.7ms ± 1% 82.2ms ± 1% -5.16% (p=0.008 n=5+5) TimeParse-4 433ns ± 3% 399ns ± 4% -7.90% (p=0.008 n=5+5) TimeFormat-4 467ns ± 2% 430ns ± 1% -7.76% (p=0.008 n=5+5) name old speed new speed delta GobDecode-4 77.9MB/s ± 1% 82.5MB/s ± 1% +5.84% (p=0.008 n=5+5) GobEncode-4 87.7MB/s ± 1% 94.0MB/s ± 1% +7.15% (p=0.008 n=5+5) Gzip-4 68.8MB/s ± 0% 67.2MB/s ± 1% -2.27% (p=0.008 n=5+5) Gunzip-4 381MB/s ± 1% 375MB/s ± 0% -1.65% (p=0.008 n=5+5) JSONEncode-4 89.9MB/s ± 5% 98.1MB/s ± 3% +9.11% (p=0.008 n=5+5) JSONDecode-4 27.6MB/s ± 3% 27.3MB/s ± 1% ~ (p=0.310 n=5+5) GoParse-4 13.2MB/s ± 3% 13.5MB/s ± 2% ~ (p=0.056 n=5+5) RegexpMatchEasy0_32-4 331MB/s ± 2% 326MB/s ± 0% ~ (p=0.151 n=5+5) RegexpMatchEasy0_1K-4 3.29GB/s ± 1% 3.27GB/s ± 0% ~ (p=0.222 n=5+5) RegexpMatchEasy1_32-4 327MB/s ± 2% 357MB/s ± 2% +9.20% (p=0.008 n=5+5) RegexpMatchEasy1_1K-4 1.97GB/s ± 0% 2.01GB/s ± 2% +1.76% (p=0.032 n=5+5) RegexpMatchMedium_32-4 6.31MB/s ± 2% 6.83MB/s ± 1% +8.31% (p=0.008 n=5+5) RegexpMatchMedium_1K-4 22.1MB/s ± 1% 21.4MB/s ± 2% -3.01% (p=0.008 n=5+5) RegexpMatchHard_32-4 12.6MB/s ± 3% 13.0MB/s ± 0% +2.98% (p=0.008 n=5+5) RegexpMatchHard_1K-4 13.4MB/s ± 0% 13.7MB/s ± 2% +2.19% (p=0.008 n=5+5) Revcomp-4 451MB/s ± 2% 479MB/s ± 1% +6.12% (p=0.008 n=5+5) Template-4 22.4MB/s ± 1% 23.6MB/s ± 1% +5.43% (p=0.008 n=5+5)
The big improvements from the switch to the SSA backend show up on non intel architectures. Here are the results for Arm64:
name old time/op new time/op delta BinaryTree17-8 10.6s ± 0% 8.1s ± 1% -23.62% (p=0.016 n=4+5) Fannkuch11-8 9.19s ± 0% 5.95s ± 0% -35.27% (p=0.008 n=5+5) FmtFprintfEmpty-8 136ns ± 0% 118ns ± 1% -13.53% (p=0.008 n=5+5) FmtFprintfString-8 472ns ± 1% 331ns ± 1% -29.82% (p=0.008 n=5+5) FmtFprintfInt-8 388ns ± 3% 273ns ± 0% -29.61% (p=0.008 n=5+5) FmtFprintfIntInt-8 640ns ± 2% 438ns ± 0% -31.61% (p=0.008 n=5+5) FmtFprintfPrefixedInt-8 580ns ± 0% 423ns ± 0% -27.09% (p=0.008 n=5+5) FmtFprintfFloat-8 823ns ± 0% 613ns ± 1% -25.57% (p=0.008 n=5+5) FmtManyArgs-8 2.69µs ± 0% 1.96µs ± 0% -27.12% (p=0.016 n=4+5) GobDecode-8 24.4ms ± 0% 17.3ms ± 0% -28.88% (p=0.008 n=5+5) GobEncode-8 18.6ms ± 0% 15.1ms ± 1% -18.65% (p=0.008 n=5+5) Gzip-8 1.20s ± 0% 0.74s ± 0% -38.02% (p=0.008 n=5+5) Gunzip-8 190ms ± 0% 130ms ± 0% -31.73% (p=0.008 n=5+5) HTTPClientServer-8 205µs ± 1% 166µs ± 2% -19.27% (p=0.008 n=5+5) JSONEncode-8 50.7ms ± 0% 41.5ms ± 0% -18.10% (p=0.008 n=5+5) JSONDecode-8 201ms ± 0% 155ms ± 1% -22.93% (p=0.008 n=5+5) Mandelbrot200-8 13.0ms ± 0% 10.1ms ± 0% -22.78% (p=0.008 n=5+5) GoParse-8 11.4ms ± 0% 8.5ms ± 0% -24.80% (p=0.008 n=5+5) RegexpMatchEasy0_32-8 271ns ± 0% 225ns ± 0% -16.97% (p=0.008 n=5+5) RegexpMatchEasy0_1K-8 1.69µs ± 0% 1.92µs ± 0% +13.42% (p=0.008 n=5+5) RegexpMatchEasy1_32-8 292ns ± 0% 255ns ± 0% -12.60% (p=0.000 n=4+5) RegexpMatchEasy1_1K-8 2.20µs ± 0% 2.38µs ± 0% +8.38% (p=0.008 n=5+5) RegexpMatchMedium_32-8 411ns ± 0% 360ns ± 0% -12.41% (p=0.000 n=5+4) RegexpMatchMedium_1K-8 118µs ± 0% 104µs ± 0% -12.07% (p=0.008 n=5+5) RegexpMatchHard_32-8 6.83µs ± 0% 5.79µs ± 0% -15.27% (p=0.016 n=4+5) RegexpMatchHard_1K-8 205µs ± 0% 176µs ± 0% -14.19% (p=0.008 n=5+5) Revcomp-8 2.01s ± 0% 1.43s ± 0% -29.02% (p=0.008 n=5+5) Template-8 259ms ± 0% 158ms ± 0% -38.93% (p=0.008 n=5+5) TimeParse-8 874ns ± 1% 733ns ± 1% -16.16% (p=0.008 n=5+5) TimeFormat-8 1.00µs ± 1% 0.86µs ± 1% -13.88% (p=0.008 n=5+5) name old speed new speed delta GobDecode-8 31.5MB/s ± 0% 44.3MB/s ± 0% +40.61% (p=0.008 n=5+5) GobEncode-8 41.3MB/s ± 0% 50.7MB/s ± 1% +22.92% (p=0.008 n=5+5) Gzip-8 16.2MB/s ± 0% 26.1MB/s ± 0% +61.33% (p=0.008 n=5+5) Gunzip-8 102MB/s ± 0% 150MB/s ± 0% +46.45% (p=0.016 n=4+5) JSONEncode-8 38.3MB/s ± 0% 46.7MB/s ± 0% +22.10% (p=0.008 n=5+5) JSONDecode-8 9.64MB/s ± 0% 12.49MB/s ± 0% +29.54% (p=0.016 n=5+4) GoParse-8 5.09MB/s ± 0% 6.78MB/s ± 0% +33.02% (p=0.008 n=5+5) RegexpMatchEasy0_32-8 118MB/s ± 0% 142MB/s ± 0% +20.29% (p=0.008 n=5+5) RegexpMatchEasy0_1K-8 605MB/s ± 0% 534MB/s ± 0% -11.85% (p=0.016 n=5+4) RegexpMatchEasy1_32-8 110MB/s ± 0% 125MB/s ± 0% +14.23% (p=0.029 n=4+4) RegexpMatchEasy1_1K-8 465MB/s ± 0% 430MB/s ± 0% -7.72% (p=0.008 n=5+5) RegexpMatchMedium_32-8 2.43MB/s ± 0% 2.77MB/s ± 0% +13.99% (p=0.016 n=5+4) RegexpMatchMedium_1K-8 8.68MB/s ± 0% 9.87MB/s ± 0% +13.71% (p=0.008 n=5+5) RegexpMatchHard_32-8 4.68MB/s ± 0% 5.53MB/s ± 0% +18.08% (p=0.016 n=4+5) RegexpMatchHard_1K-8 5.00MB/s ± 0% 5.83MB/s ± 0% +16.60% (p=0.008 n=5+5) Revcomp-8 126MB/s ± 0% 178MB/s ± 0% +40.88% (p=0.008 n=5+5) Template-8 7.48MB/s ± 0% 12.25MB/s ± 0% +63.74% (p=0.008 n=5+5)
These are pretty big improvements from just recompiling your binary.
Defer and cgo improvements
The question of if defer can be used in hot code paths remains open, but during the 1.8 cycle Austin reduced the overhead of using defer by a half, according to some benchmarks.
The runtime package benchmarks are a little less rosy.
name old time/op new time/op delta Defer-4 101ns ± 1% 66ns ± 0% -34.73% (p=0.000 n=20+20) Defer10-4 93.2ns ± 1% 62.5ns ± 8% -33.02% (p=0.000 n=20+20) DeferMany-4 148ns ± 3% 131ns ± 3% -11.42% (p=0.000 n=19+19)
According to them defer improved by a third in most common circumstances where the statement closes over no more than a single variable.
Additionally, an optimisation by David Crawshaw reduced the overhead of defer in the cgo path by nearly half.
name old time/op new time/op delta CgoNoop-8 93.5ns ± 0% 51.1ns ± 1% -45.34% (p=0.016 n=4+5)
One more thing
Go 1.7 supported 64 bit mips platforms, thanks to the work of Minux and Cherry. However, the less powerful but plentiful, 32 bit mips platforms were not supported. As a bonus, thanks to the work of Vladimir Stefanovic, Go 1.8 will ship will support for 32 bit mips.
% env GOARCH=mips go build -o godoc.mips golang.org/x/tools/cmd/godoc % file godoc.mips godoc.mips: ELF 32-bit MSB executable, MIPS, MIPS32 version 1 (SYSV), statically linked, not stripped
While 32 bit mips hosts are probably too small to compile Go programs natively, you can always cross compile from your development workstation for linux/mips.