This is the first in a series of articles analysing the performance improvements in the Go 1.1 release.
It has been reported (here, and here) that performance improvements of 30-40% are available simply by recompiling your code under Go 1.1. For linux/amd64 this holds true for a wide spectrum of benchmarks. For platforms like linux/386 and linux/arm the results are even more impressive, but I’m putting the cart before the horse.
A note about gccgo. This series focuses on the contributions that the improvements to the gc series of compilers (5g, 6g and 8g) have made to Go 1.1’s performance. gccgo benefits indirectly from these improvements as it shares the same runtime and standard library, but is not the focus of this benchmarking series.
Go 1.1 features several improvements in the compilers, runtime and standard library that are directly attributable for the resulting improvements in program speed. Specifically
- Code generation improvements across all three gc compilers, including better register allocation, reduction in redundant indirect loads, and reduced code size.
- Improvements to inlining, including inlining of some
builtinfunction calls and compiler generated stub methods when dealing with interface conversions. - Reduction in stack usage, which reduces pressure on stack size, leading to fewer stack splits.
- Introduction of a parallel garbage collector. The collector remains mark and sweep, but the phases can now utillise all CPUs.
- More precise garbage collection, which reduces the size of the heap, leading to lower GC pause times.
- A new runtime scheduler which can make better decisions when scheduling goroutines.
- Tighter integration of the scheduler with the
netpackage, leading to significantly decreased packet processing latencies and higher throughput. - Parts of the runtime and standard library have been rewritten in assembly to take advantage of specific bulk move or crypto instructions.
Introducing autobench
Few things irk me more than unsubstantiated, unrepeatable benchmarks. As this series is going to throw out a lot of numbers, and draw some strong conclusions, it was important for me to provide a way for people to verify my results on their machines.
To this end I have built a simple make based harness which can be run on any platform that Go supports to compare the performance of a set of synthetic benchmarks against Go 1.0 and Go 1.1. While the project is still being developed, it has generated a lot of useful data which is captured in the repository. You can find the project on Github.
https://github.com/davecheney/autobench
I am indebted to Go community members who submitted benchmark data from their machines allowing me to make informed conclusions about the relative performance of Go 1.1.
If you are interested in participating in autobench there will be a branch which tracks the performance of Go 1.1 against tip opening soon.
A picture speaks a thousand words
To better visualise the benchmark results, AJ Starks has produced a wonderful tool, benchviz which turns the dry text based output of misc/benchcmp into rather nice graphs. You can read all about benchviz on AJ’s blog.
http://mindchunk.blogspot.com.au/2013/05/visualizing-go-benchmarks-with-benchviz.html
Following a tradition set by the misc/benchcmp tool, improvements, be they a reduction in run time, or an increase in throughput, are shown as bars extending towards the right. Regressions, fall back to the left.
Go 1 benchmarks on linux/amd64
The remainder of this post will focus on linux/amd64 performance. The 6g compiler is considered to be the flagship of the gc compiler suite. In addition to code generation improvements in the front and back ends, performance critical parts of the standard library and runtime have been rewritten in assembly to take advantage of SSE2 instructions.
The data for the remainder of this article is taken from the results file linux-amd64-d5666bad617d-vs-e570c2daeaca.txt.
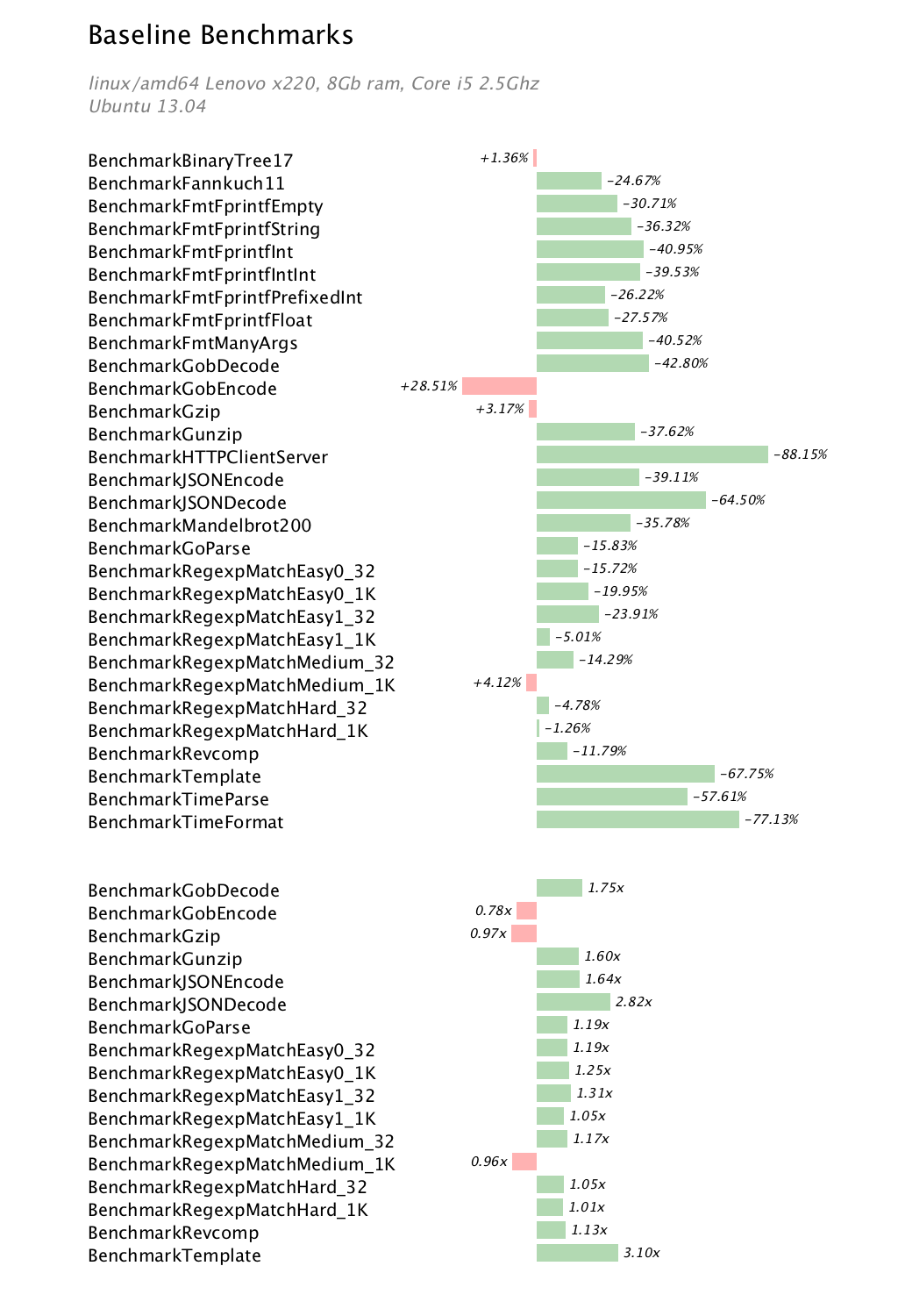
The go1 benchmark suite, while being a synthetic benchmark, attempts to capture some real world usages of the main packages in the standard library. In general the results support the hypothesis of a broad 30-40% improvement. Looking at the results submitted to the autobench repository it is clear that GobEncode and Gzip have regressed and issues 5165 and 5166 have been raised, respectively In the latter case, the switch to 64 bit ints is assumed to be at least partially to blame.
net/http benchmarks
This set of benchmarks are extracted from the net/http package and demonstrated the work that Brad Fitzpatrick and Dmitry Vyukov, and many others, have put into net and net/http packages.
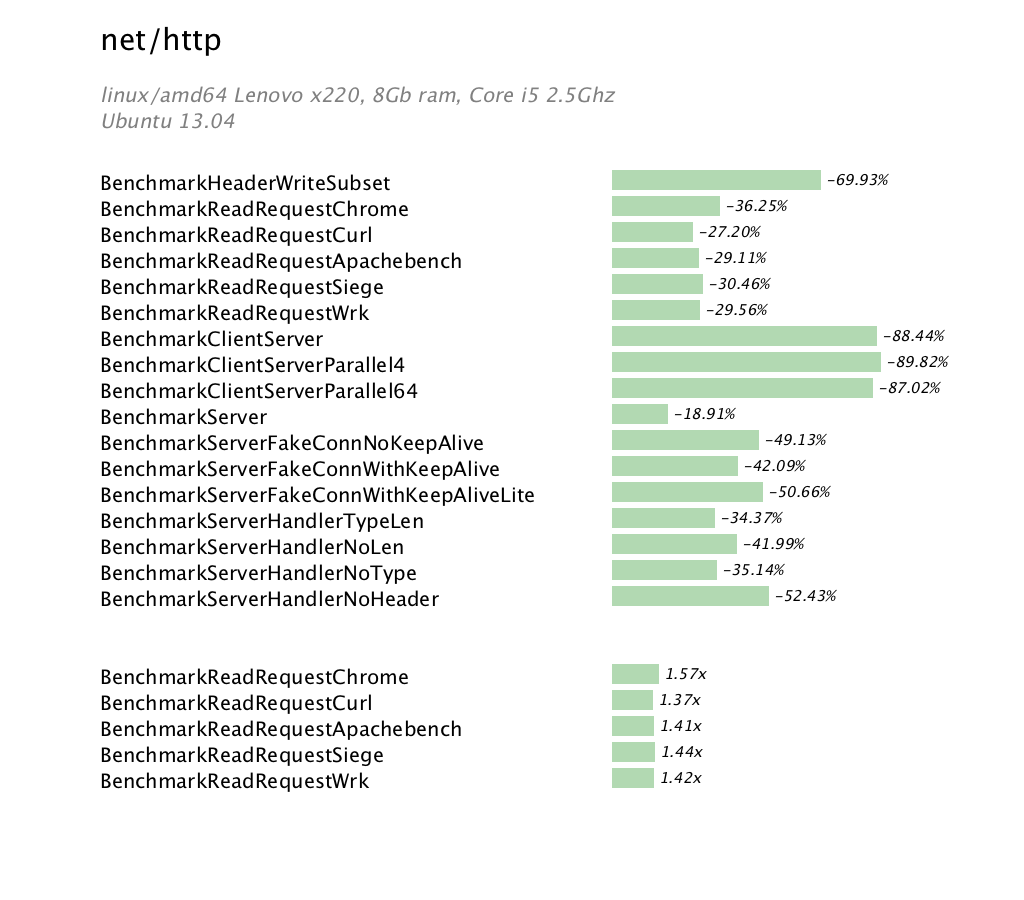
Of note in this benchmark set are the improvements in ReadRequest benchmarks, which attempt to benchmark the decoding a HTTP request. The improvements in the ClientServerParallel benchmarks are not currently available across all amd64 platforms, as some of them have no support for the new runtime integration with the net package. Finishing support for the remaining BSD and Windows platforms is a focus for the 1.2 cycle.
Runtime microbenchmarks
The final set of benchmarks presented here are extracted from the runtime package.
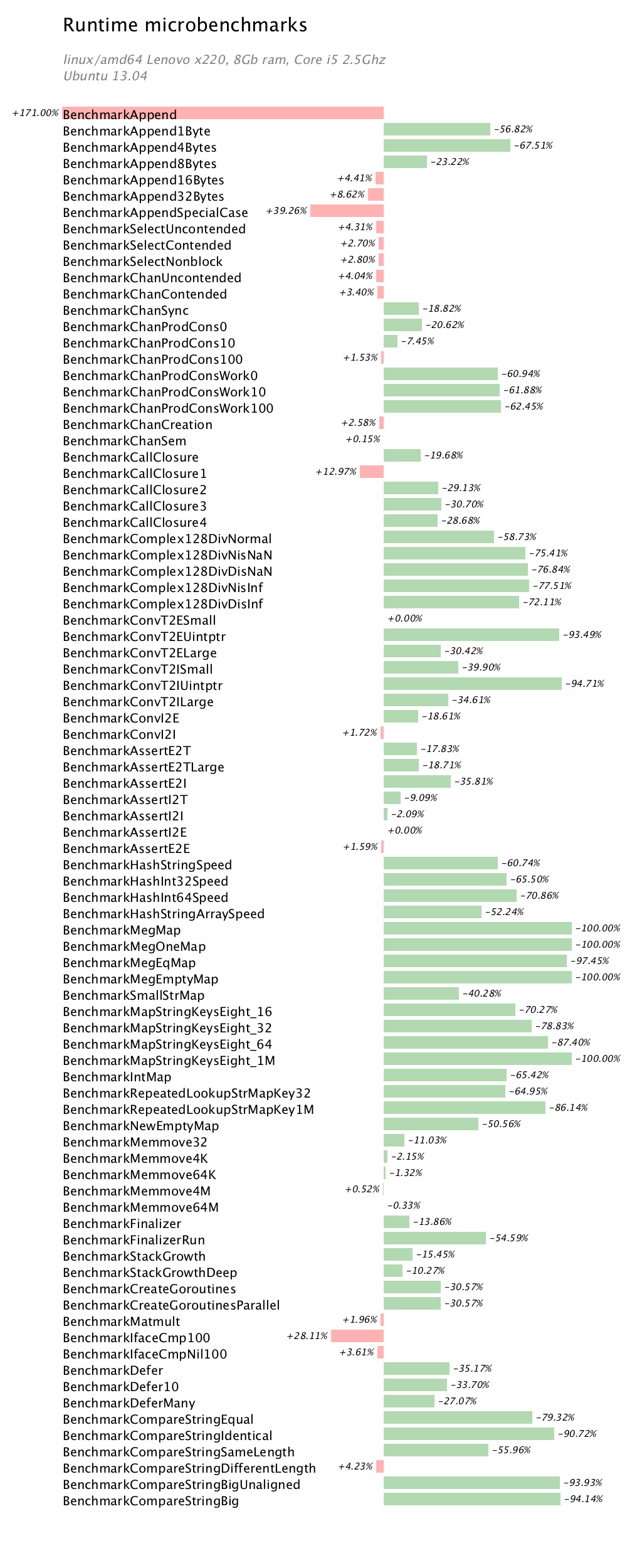
The runtime benchmarks represent micro benchmarks of very low level parts of the runtime package.
The obvious regression is the first Append benchmark. While in wall time, the benchmark has increased from 36 ns/op to 100 ns/op, this shows that for some append use cases there has been a regression. This may have already been addressed in tip by CL 9360043.
The big wins in the runtime benchmarks are the amazing new map code by khr which addresses issue 3886, the reduction in overhead of channel operations (thanks to Dmitry’s new scheduler), improvements in operations involving complex128 operations, and speedups in hash and memmove operations which were rewritten in 64bit assembly.
Conclusion
For linux/amd64 on modern 64 bit Intel CPUs, the 6g compiler and runtime can generate significantly faster code. Other amd64 platforms share similar speedups, although the specific improvements vary. I encourage you to review the benchmark data in the autobench repository and if you are able, submit your own results.
In subsequent articles I will investigate the performance improvement Go 1.1 brings to 386 and arm platforms.
Update: thanks to @ajstarks who provided me with higher quality benchviz images.
FWIW, based on:
https://code.google.com/p/gofrontend/source/list
I don’t think gccgo trunk has received any of the standard library enhancements since 1 March 2013.
Actually, I think the last update might have been on 29 January 2013.
Very likely, I heard that gccgo 4.8.1 will receive the full Go 1.1 standard library.
“The big wins in the runtime benchmarks are the amazing new map code by khr which addresses issue 3886”
But the link has that issue labeled as “Go1.2Maybe”?
Very interesting results from benchmarks, thanks for the post !!!!
“…it is clear that GobDecode and Gzip have regressed…” Typo? The chart indicates it is GobEncode that regressed.
You are quite correct. Thank you, I have fixed the mistake.
Pingback: Go 1.1 performance improvements | thoughts...
Pingback: Sorting Localized Strings | Khuram Ali
I looked at the Go language in a moderate amount of depth. Unfortunately there is nothing so much for desktop applications developers. The particular issue for me is dll access. For sure a bad programmer can turn shared library features into demonic hell. In the hands of a good programmer shared libraries are a super slick way of integrating code together in a neat and tidy way. DLL’s have well defined interfaces and are very clear and simple to use.
This would allow Go to access GUI code for example.
I know that Go does have some bonkers DLL access but that is a mess. Also the CGo mixed language metaphor is a horrible mess. Both could be replaced by intelligent shared library access built into the language itself.
I think the Go language design team have made a fundamental mistake not allowing shared libraries and the language may not take off as a result.